In healthcare settings, accurately capturing and understanding clinician-patient dialogues is crucial for effective patient care and medical documentation. Traditional methods of transcription can be time-consuming and prone to errors. Moreover, handwritten notes by doctors can sometimes be challenging to decipher, leading to potential misunderstandings or delays in patient treatment.
Esperanto has explored one of the SOTA audio-to-text models, Whisper, and adapted it to our ET-SoC-1 architecture. We also converted Whisper from PyTorch to ONNX and provided ONNX models in FP16 precision to the Huggingface community. Please check our past blog for more information.
Even though Whisper performs well on day-to-day topics, it has not necessarily been trained on domain-specific data like medical conversations and the performance of the model on such datasets is not as good as its usual performance on general day-to-day topics. This gap highlights the need for specialized training and fine-tuning to ensure Whisper can effectively handle the intricacies of medical conversations, such as the complex terminology of diseases.
By leveraging and enhancing state-of-the-art machine learning models, we aim to revolutionize this process by providing precise and real-time transcriptions of medical conversations. This advancement not only enhances the efficiency of medical professionals, but also improves the quality and accessibility of patient records, ultimately leading to better healthcare outcomes. Our initiative seeks to bridge the gap between technology and healthcare, ensuring that every patient interaction is accurately documented.
Figure 1: Medical Whisper Demo
Data Source and Introduction
We gather the data from the following repository.
This repository contains the data and annotations described in the following papers:
- PriMock57: A Dataset Of Primary Care Mock Consultations
- Human Evaluation and Correlation with Automatic Metrics in Consultation Note Generation
The dataset consists of 57 mock medical primary care consultations held over 5 days by 7 Babylon clinicians and 57 Babylon employees acting as patients, using case cards with presenting complaints, symptoms, medical & general history, and more. The data in this repository includes:
- Audio recordings of the consultations (audio folder);
- Manual utterance-level transcriptions of the recordings (transcripts folder);
- Consultation notes written by the consulting clinicians (notes folder);
- Human evaluation annotations & data (human_eval_data folder).
- Additional information:
- Total audio duration is 8h:38m.
- Audio is saved in wav 16bit/16khz format.
Audio Chunk Example
Audio Example Transcript:Hello Hello. Hello there. It's uh Doctor here. How can I help you this afternoon? Ohh I just got a terrible headache since mid-day. Um on the left side. It's just making me feel so ill. I just feel like I need to vomit. I'm sorry to hear that. Um can you tell me a bit more about the headache? Well you know I noticed some zig-zag lines in my vision a few minutes before the headache started. Mm-hmm. My vision blurred. Um uh
Data Processing
We need to perform a good amount of preprocessing to merge the initially separated Doctor/Patient audio channels and to make the data “Whisper Ready”.
First, we need to merge channels. After downloading data from the repository, we store it as a DataFrame, where the column “path“ points to the path where the audio is stored and the column “transcript“ contains the target words that were pronounced in the corresponding audio. Then, we parse the text to remove special characters and parse the audio files to get the corresponding audio signals in arrays.
Figure 2: Audio Signal Example
Finally, to make the data “Whisper Ready“, we perform 3/5; 1/5; 1/5 train-val-test split. Upon reading the paper, we learned that Whisper is designed to handle audio inputs with a maximum length of 30 seconds. In inference, it will truncate any audio that is longer than 30 seconds. During our fine-tuning, we manually split the audios and link them to their corresponding labels. After the audio and corresponding text are ready, we transform the dataset to a Hugging Face DatasetDict object.
Benchmarking
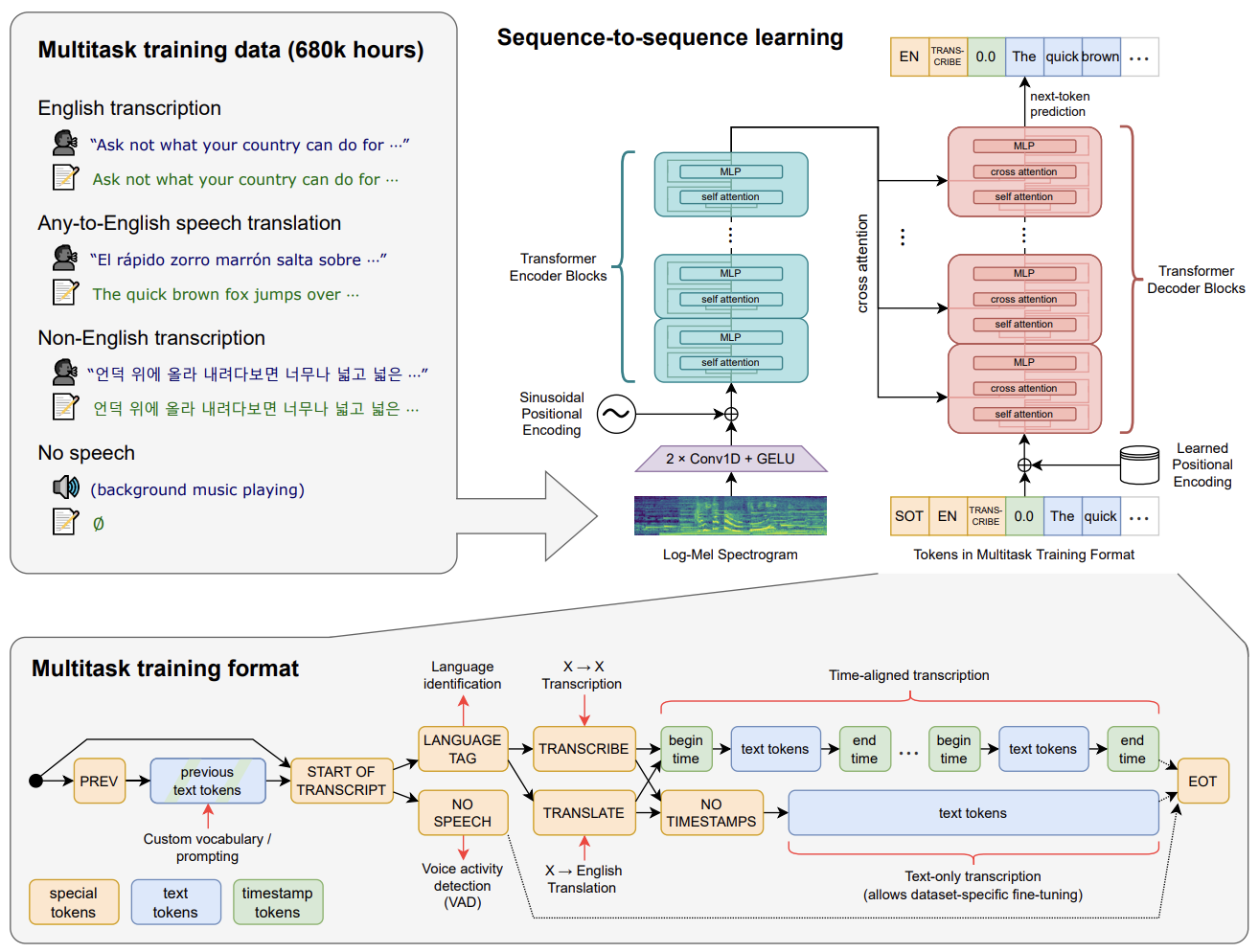
Figure 3: Overview of Model Architecture from the Whisper Paper
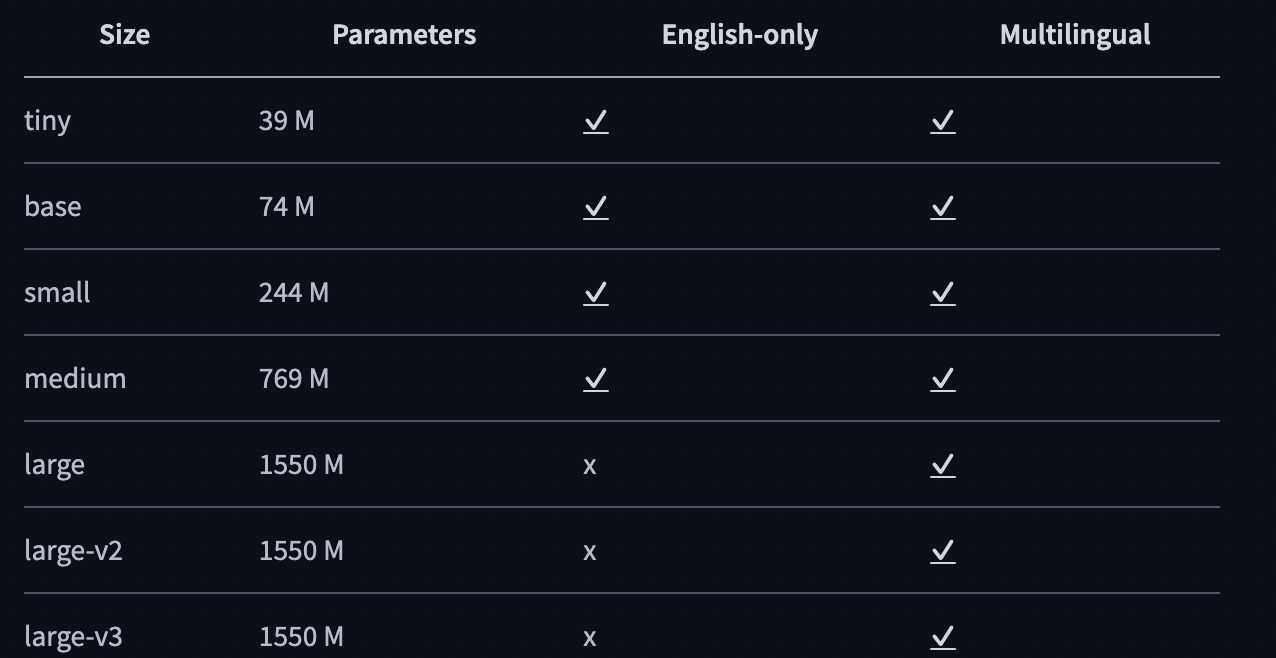
Figure 4: Whisper Overview
Step 1: Load the foundation model, its processor and its tokenizer.
Step 2: Load “WER” and “CER” metrics.
Word Error Rate (WER) measures the percentage of words that are incorrectly predicted or transcribed. It is calculated using the following formula:
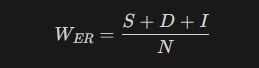
S: the number of substitution errors (words that were present but are incorrectly transcribed).
D: the number of deletion errors (words that were present in the reference but are missing in the prediction).
I: the number of insertion errors (extra words that were not in the reference).
N: the total number of words in the reference.
Character Error Rate (CER)
CER measures the percentage of characters that are incorrectly predicted or transcribed. It is calculated using the following formula:
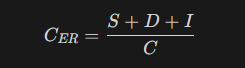
The definition of S, D and I are the same as in WER. Aside from that, C is the total number of characters in the reference.
Step 3: Run Whisper speech recognition on the validation set.
Step 4: Get performance by comparing predictions and labels through “WER” and “CER” metrics.
Fine-Tuning Through Transfer Learning
We start with loading the foundation model, its processor and its tokenizer.
model.generation_config.language = "en" model.generation_config.task = "transcribe"
On top of loading the model, some hyperparameters need to be fixed beforehand. In this case, those hyperparameters are the language (that is set to English) and the task we want the model to perform (which is transcription), since Whisper can perform a collection of tasks, such as translation.
In the second step, we need to ready up the data and create a DataCollator class.
# #### Define fine tuning data class
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [
{"input_features": feature["input_features"][0]} for feature in features
]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
return batch
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
This part is especially important since Whisper has a special format of data that it accepts. Therefore, we introduce a DataCollator class where we can split inputs and labels, transform the audio signal to tensors, tokenize the labels, and pad the inputs and the labels.
Next, we chose to directly load Hugging Face training_args and trainer object and pass the training arguments defined above in the hyperparameter “args”.
# #### Define fine tuning arguments
training_args = Seq2SeqTrainingArguments(
output_dir="./Medical_Whisper_large_v3_1.0", # name on the HF Hub
per_device_train_batch_size=6,
gradient_accumulation_steps=4, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5, # usual learning rate for such models
lr_scheduler_type="constant_with_warmup", # usual scheduler for such models
warmup_steps=50,
max_steps=500,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={'use_reentrant':False},
fp16=True, # model precision
eval_strategy="no", # We will be evaluating the model manually at the end of the fine-tuning hence this choice
do_eval=False,
per_device_eval_batch_size=6,
predict_with_generate=True, # We use the previous generated tokens for the attention mechanism
generation_max_length=225, # We're passing chunked audios of 30 seconds. Therefore, they do not contain more than 225 words spoken (over-estimation)
save_steps=500, # We save the new weights every 500 steps in case we experience a crash
logging_steps=25, # We output the loss every 25 steps to verify that it is decreasing and that therefore, the model is learning
report_to=["wandb"], # We use the platform weights and biases to track the training
metric_for_best_model="wer",
greater_is_better=False, # a big word error rate means that the model is underperforming compared to a lowest word error rate
push_to_hub=True, # We are pushing the new weights to the hub every 500 steps in case we experience a crash, so that we have them locally and on the hub as well
)
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=Data["train"],
data_collator=data_collator,
tokenizer=processor,
)
Finally, launch the trainer on the collated training data and push the model to the hub upon fine-tuning.
# This line of code launches the fine-tuning
trainer.train()
# kwargs contains the different values of the tags we're pushing the model to the hub with
kwargs = {
"dataset_tags": "medical_data",
"dataset": "primock_data + Hani89_data",
"dataset_args": "None",
"language": "en",
"model_name": "Medical_Whisper_large_v3_1.0",
"finetuned_from": "openai/whisper-large-v3",
"tasks": "automatic-speech-recognition",
}
trainer.push_to_hub(**kwargs)
The model is now fine-tuned with respect to the training arguments and pushed to the hub with respect to the kwargs.
Esperanto has already made Whisper’s architecture compatible with ET-SoC-1 in the past: Blog: Adapting Whisper Models to ET-SoC-1 Architecture and Exporting Them to ONNX. The model is also available on our HuggingFace page here.
Results
| Model Name | WER | CER | Number of Parameters |
| Whisper Tiny | 0.46 | 0.27 | 39M |
| Whisper Base | 0.42 | 0.26 | 74M |
| Whisper Small | 0.39 | 0.26 | 244M |
| Whisper Medium | 0.37 | 0.23 | 769M |
| Whisper Large v3 | 0.33 | 0.18 | 1.55B |
| Whisper Medical | 0.19 | 0.10 | 1.55B |
Figure 5: Performance of Foundation Whispers vs Medical Whisper on the Validation Set
| Model Name | WER | CER |
| Whisper Medical | 0.24 | 0.13 |
Figure 6: Performance of Medical Whisper on the Test Set (Generalization Ability)
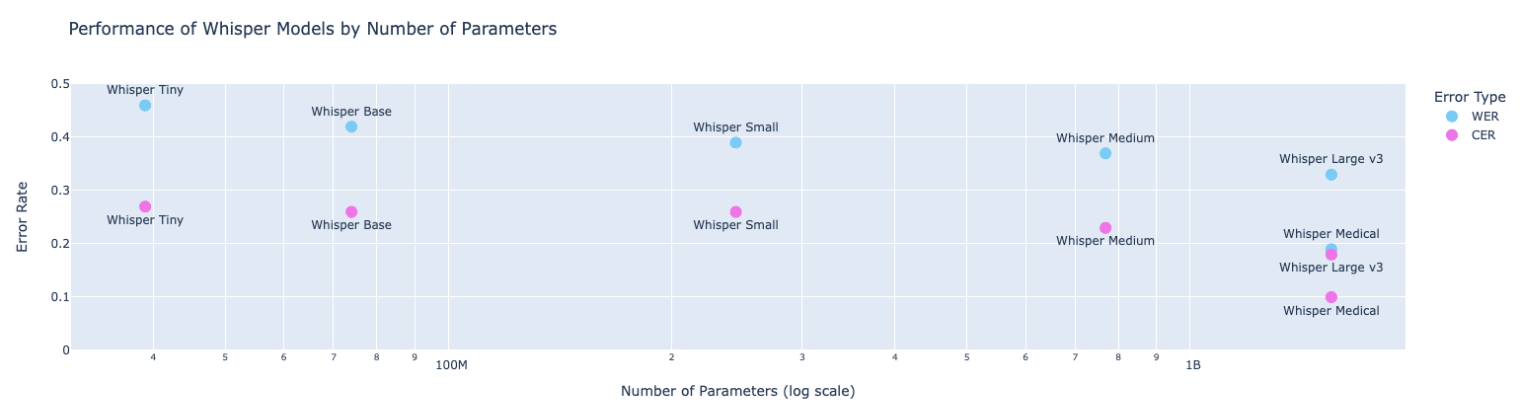
Figure 7: Performance of Medical Whisper Based on Number of Parameters
The performance comparison between foundation Whisper models and the specialized Whisper Medical model on the validation set highlights significant improvements in transcription accuracy for the medical domain. Whisper Medical achieves a Word Error Rate (WER) of 0.19 and a Character Error Rate (CER) of 0.10, outperforming all foundation models, including Whisper Large v3. Whisper Medical demonstrates superior domain-specific optimization.
On the test set, Whisper Medical maintains strong generalization capability, achieving a WER of 0.24 and a CER of 0.13, further showcasing its robustness in handling unseen medical transcription tasks.
Speaker Recognition
In our first draft, the output script is stacked together and is not easy for reading or for the next step of summarizing the content.
Example of the first draft:
Hello? Hello. How are you? Hi. Um should we start? Yeah okay. Hello how um. Good morning sir how can I help you this morning? Hi um I’ve just had some um diarrhea for the last three dats um and it’s been affecting me I need to stay close to the toilet. And um yeah it’s been affecting my day-to-day activities. I’m sorry to hear that. Um and and when you say diarrhea what do you mean……
Intuitively, we proposed two solutions to implement speaker recognition:
- Post-processing: Utilize a lightweight model like phi-3-mini for post-processing. Given the fact that this passage is the transcript between the doctor and patient, let the LLM distinguish the speaker without changing the content.
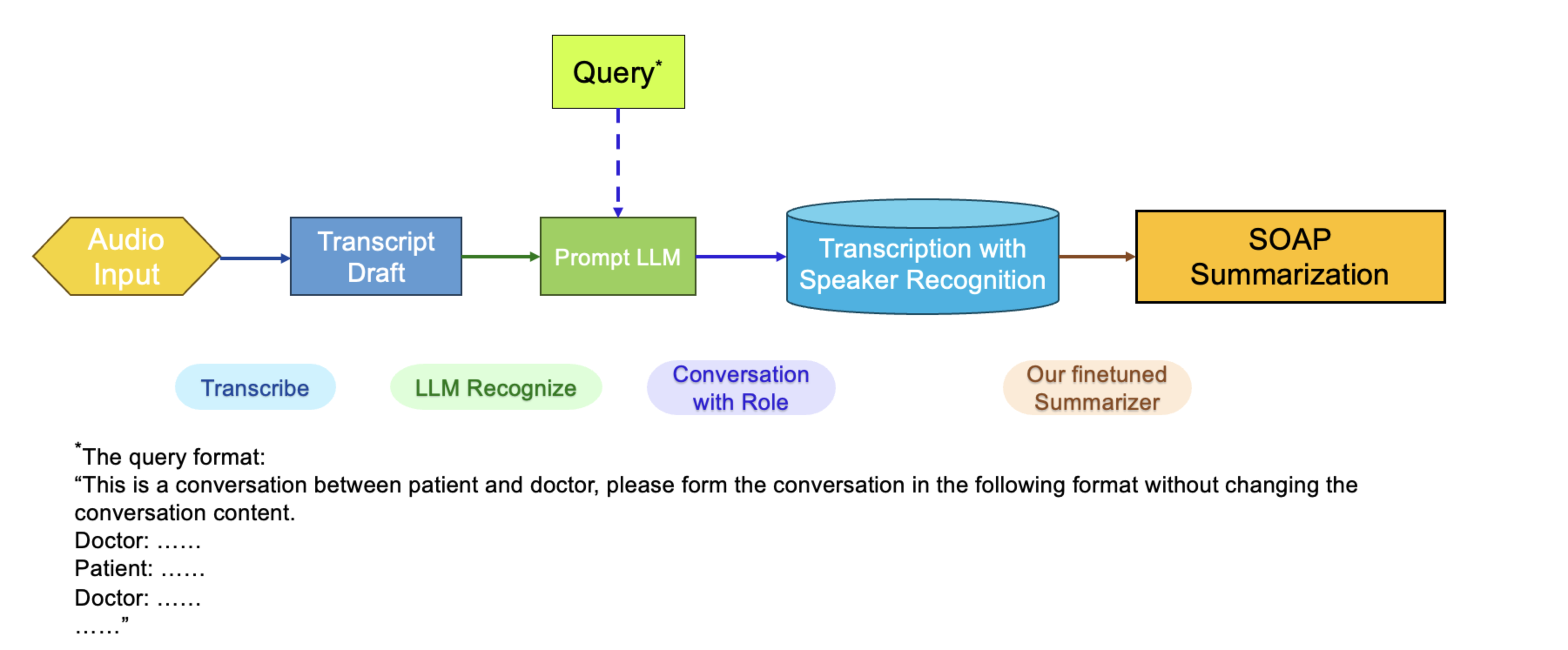
Figure 8: Pipeline Summarization for Adding Post-Processing
-
Preprocessing: Use Pyannote to do speaker recognition. Truncate the audio based on Pyannote clustering output, and use as input for the fine-tuned Medical Whisper model.
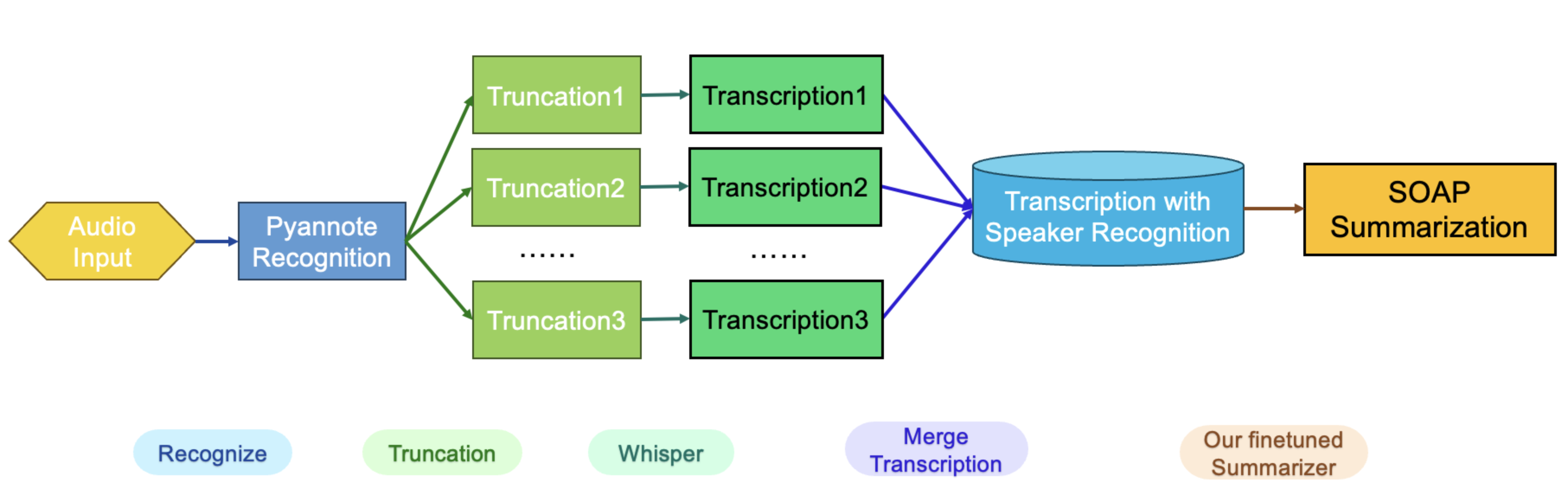
Figure 9: Pipeline Summarization for Adding Pyannote PreProcessing
Since our goal is to generate different speakers’ realtime transcription, method 2 is used in our demo pipeline. Upon further research, we discover that Pyannote is one of the SOTA model in speaker recognition application. Providing the fixed number of speakers, Pyannote is able to perform clustering based on speech representation, and returns re-segmentation.
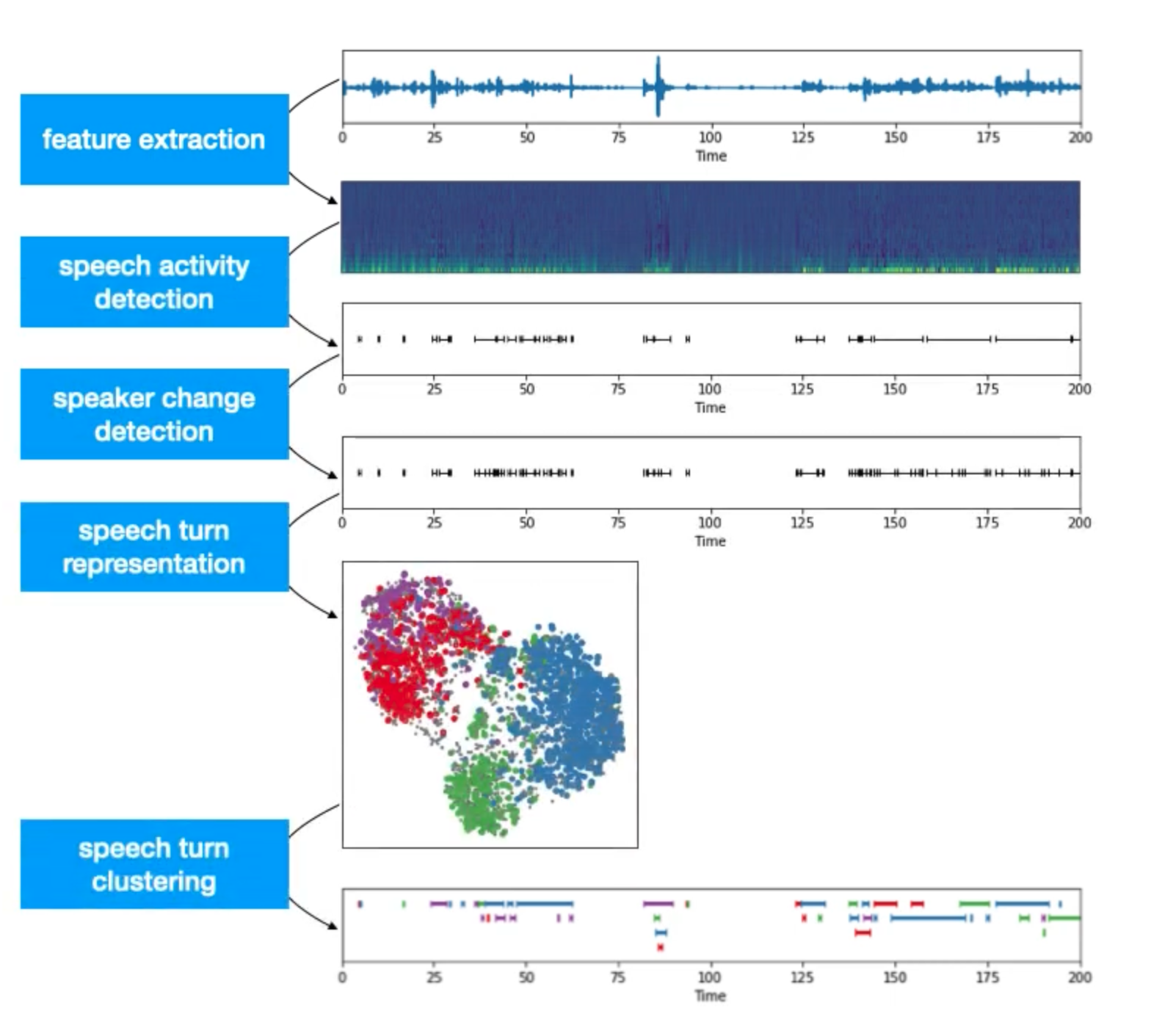
Figure 10: Pyannote Pipeline
Based on the re-segmentation points, we truncate the audio every time we detect a speaker change. And we control the speed of word generated by Medical Whisper based on each trunk’s length.
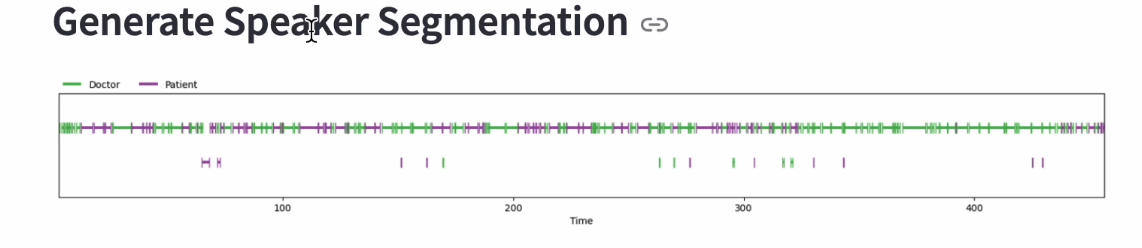
Figure 11: Speaker Recognition Example