GENERATIVE AI
Performance, efficiency, security and flexibility
for the fast-changing world of Generative AI
for the fast-changing world of Generative AI
Generative AI is moving fast, and Esperanto is moving right with it. Our current generation silicon and software are running the latest open-source Large Language Models (LLMs) stretching into the tens of billions of parameters per chip. We believe that the future of Generative AI for business will run private applications tailored for vertical market use cases such as data summarization, and code generation and translation, so we have leveraged our leading-edge technology and LLMs to develop high-density appliances for deployment of tailored Generative AI models.


Our AI / HPC Compute Servers crunch through
large language models efficiently and securely
large language models efficiently and securely
Our compute servers feature thousands of 64-bit RISC-V compute cores, each with a vector/tensor unit, delivering high performance to handle the significant AI math required to process LLMs. Esperanto’s Generative AI software stack easily compiles LLMs to efficiently partition their layers across our sophisticated fabric of compute and on-chip memory subsystems. And our application software interface enables you to integrate the system with your chat (or other) front-end user interface. With your own Esperanto Generative AI solution, you can securely build your custom LLM-based business applications to enjoy industry-leading total cost of ownership without needing costly and power-hungry GPUs.
INNOVATIVE TECHNOLOGY
Our chips use an innovative low-power approach to deliver
an exceptional value proposition for key AI and HPC applications.
an exceptional value proposition for key AI and HPC applications.
Thanks to an array of over a thousand low-power ET-Minion cores, we deliver energy efficiency with high integer and floating-point throughput, including tensor and vector acceleration optimized for ML / DL workloads. At the same time, our distributed memory architecture improves processing utilization and relieves memory bandwidth bottlenecks.
The ET-Minion on-chip RISC-V core
is designed for energy-efficient
machine learning and HPC computation.
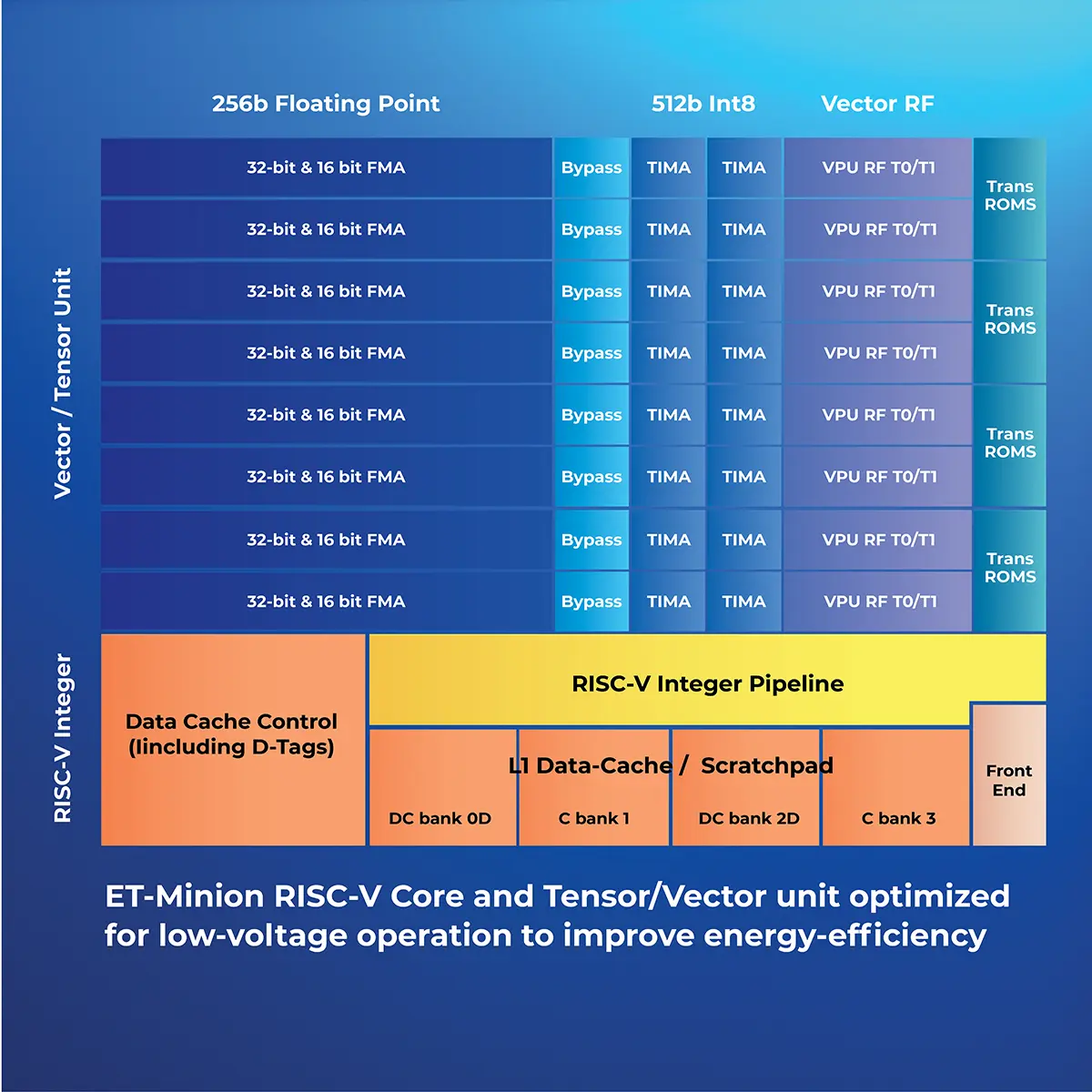
This general-purpose 64-bit microprocessor executes instructions in order, for maximum efficiency, while extensions support vector and tensor operations on up to 256 bits of floating-point data (using 16-bit or 32-bit operands) or 512 bits of integer data (using 8-bit operands) per clock cycle. Multiply-accumulate operations always work with 32-bit accumulators to avoid loss of precision for large arrays, a real problem for competing products that accumulate to smaller representations. The longest tensor operations execute for 512 cycles without consuming memory bandwidth or power to fetch and decode instructions. These operations are perfectly matched to the execution units; both run at full speed for the full duration of each operation.


The ET-Maxion on-chip RISC-V core
cluster runs SMP Linux and applications
to enable self-hosted operation.
This custom 64-bit single-thread RISC-V microprocessor core implements advanced features such as quad issue out-of-order execution, branch prediction, and sophisticated prefetching algorithms to deliver high single-thread performance. It runs the Linux operating system (and others) along with applications. Four ET-Maxion cores are on each chip, along with fully coherent cache memory. ET-Maxion cores are ideal for scheduling tasks across the array of ET-Minion cores, managing data movement and hosting operating systems. In an accelerator configuration, this offloads host processing tasks, delivering better overall system performance per dollar.
Machine Learning development tools
convert your trained model into an
optimized application spanning multiple chips.
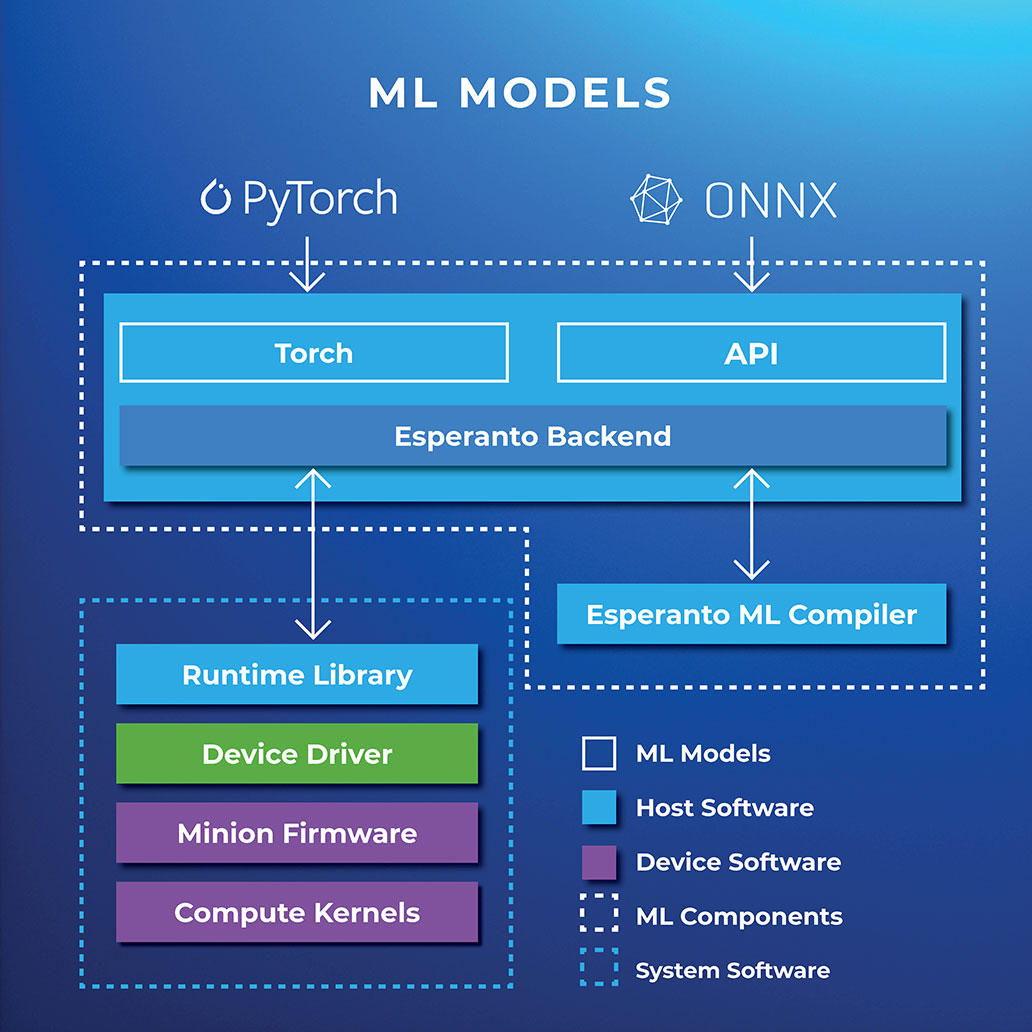
Programming sophisticated AI chips is historically difficult and time consuming. Fortunately, Esperanto has already done the heavy lifting for the major ML frameworks, including PyTorch and TensorFlow (via ONNX). Building on RISC-V open-source ecosystems, our host-based software development tools are designed to convert your trained model into an optimized package of code and data that will run efficiently on our architecture. We’re even able to run large language models (LLMs) common in Generative AI.
General purpose software development
tools let you directly program 1,000s of CPUs, unlike any other AI accelerator.
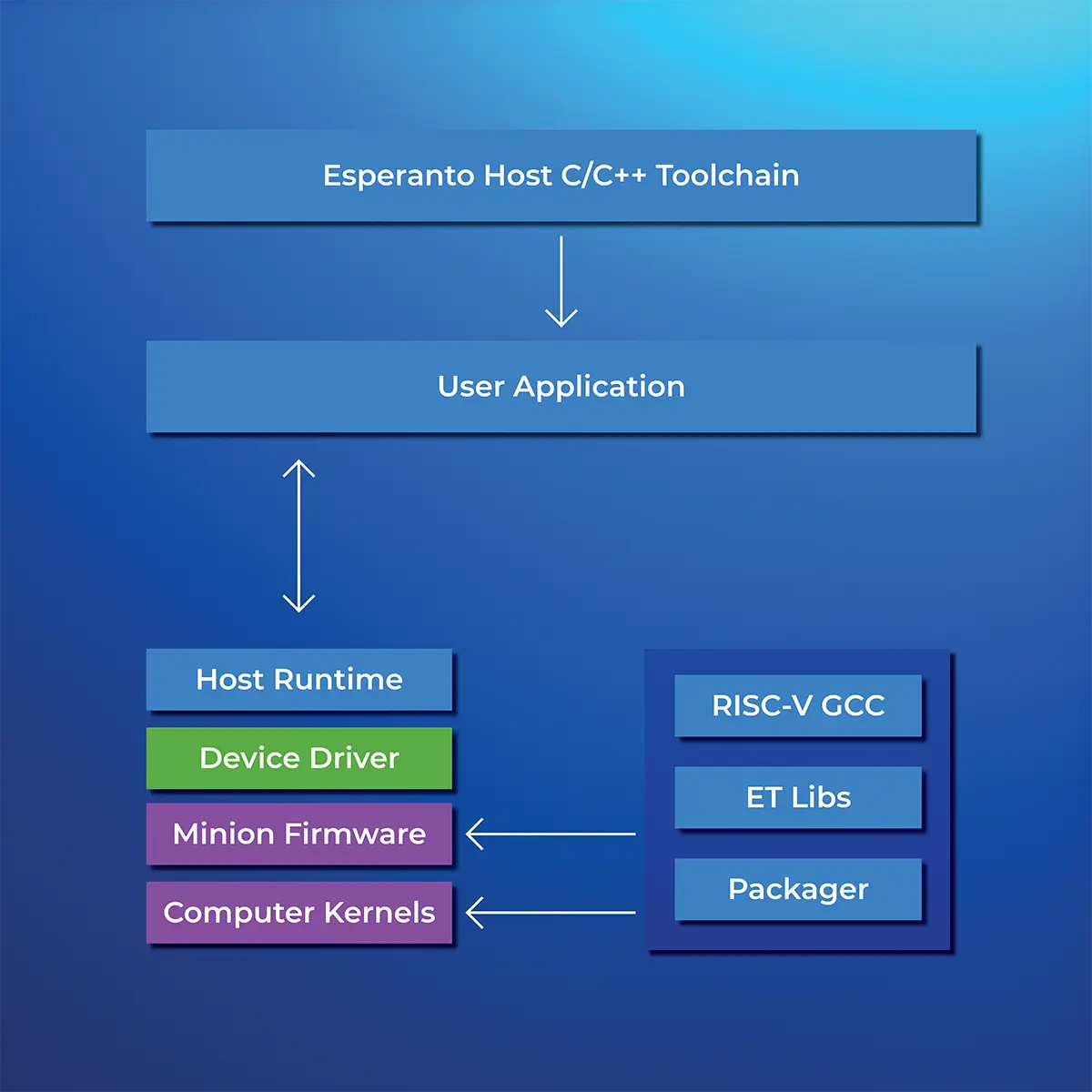
Unlike other AI accelerators, ET-SoC-1 is made up of over 1,000 general purpose 64-bit RISC-V CPUs, each supercharged with a vector/tensor unit for the linear and nonlinear math that you typically find in AI applications. This makes ET-SoC-1 an ideal platform for accelerating non-AI parallel workloads such as DSP applications. Esperanto’s General Purpose Software Development Kit enables the direct programming of all cores in its massively parallel compute fabric, and we continue to work with leading HPC/supercomputing experts to further our unique architecture. So, whether you are are combining AI and HPC workloads on the same device, or have a great HPC application to accelerate, ET-SoC-1 is the most flexible and scalable choice.
The Esperanto RISC-V architecture is an
extremely scalable and flexible solution for
virtually any application.
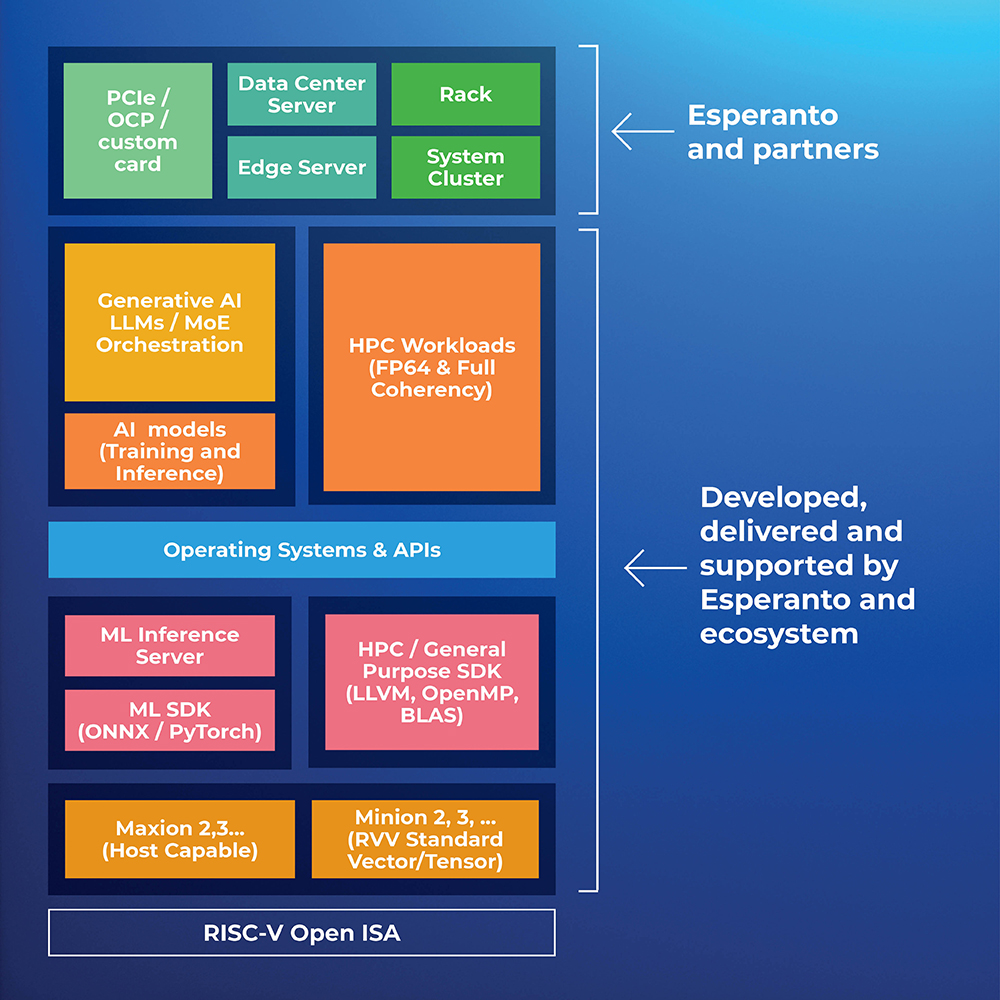
Our RISC-V architecture delivers a highly scalable solution for widely different applications, different levels of performance, different power profiles, and varying system form factors. This flexibility delivers optimal energy efficiency for each target application with a family of architecturally consistent products. With over a thousand high-performance, energy-efficient 64-bit RISC-V cores on one chip, the Esperanto ET-SoC-1 can deliver TeraOps of scalable compute performance.

Our advanced architecture is already being enhanced to accelerate the next generation of Generative AI large language models and HPC workloads.
Esperanto is already designing the next generation of its unique architecture, building on the strengths of ET-SoC-1 and leveraging RISC-V open standards. We are developing Exascale systems that will have the performance and memory bandwidth to accelerate the next generation of Generative AI models as well as HPC workloads. With enhanced Minion and Maxion cores, our next generation chip will take on training tasks in addition to inference, and our RVV-compatible vector/tensor units will crunch through everything from 64-bit HPC workloads to 8-bit floating point AI inferencing. And with our emphasis on low power design, we expect to continue to deliver industry-leading low TCO.
Request Access to
Esperanto Systems
Esperanto Systems