Overview
Large language models (LLMs) are extremely powerful when it comes to language modeling. Yet, they still present challenges that are subjects of very intensive research. One of these challenges is the context window size. In this blog post, we propose a quick overview of the issue raised by the context window length, a couple of techniques developed to increase this length and our fine-tuning experiments – followed by our take-aways.
The Problem
Let’s provide some background information. Why is it important to have a long context window? Well, although ChatGPT’s interface might have led you to think otherwise, LLMs do not have memory. Their output is solely based on the single input you feed them. What ChatGPT does to create a chat experience is concatenate the previous questions and answers, along with the most recent user’s question and feed it as a single input to the model. This virtually creates a chat history the model can use to perfect its next answer. Because of this concatenation, the input length can quickly expand and the context window size will contain the ‘memory’ of the model. When going over the size limit, one may experience a performance drop until a complete loss of sense in the generated text (though ChatGPT will never present such behavior as the input is actually truncated when too large).
Other examples of why we could use large context windows include working with large documents (books), code generation at a repository level, multi-modal systems with images corresponding to hundreds of tokens, or models working with RAG.
The Obstacles
Given this, it would appear natural to build and pre-train models with a very large context window so they can be used for a wide range of applications, including the ones requiring long-context inputs. However, doing so is both time-consuming and costly.
Quadratic Attention
In the Transformer architecture, an extremely popular architecture for LLMs and other applications, the attention block, which could be designated as the most important one, is also a computational bottleneck. Indeed, the attention block computes the attention scores that are then used by the model to understand relations between the words. This block works in a way that all words have to attend to all other words (this is done by two sequential matrix-multiplications) which results in a quadratic complexity. Because of these computations, a text input sequence of size n has a computational cost of n^2. Thus training on longer sequences is both time-consuming and extremely costly. Although, thanks to advanced innovation (such as FlashAttention) pre-trained LLMs’ context window has been increased (x4, x8) over the last year, we are quickly facing the limits of hardware requirements preventing us to consistently continue this increase.
A solution to this constraint would be to reduce the complexity of the attention block for a linear computational cost. Over the last year, many scientists have gone this way exploring the possibilities of approximating the original attention formula to a sparse attention: “sparse attention” designates a large group of methods that develop tricks and new ideas to reduce the complexity of the attention block while keeping a similar behavior and efficiency. This allows the scientist to trade full precision attention for a reduced complexity. Some of these methods reach nearly linear complexity while preserving excellent performance.
Position Encoding
When introduced, the Transformer came as a revolution: its nature allowed parallel-word training making it wildly efficient for LLMs that require a humongous amount of training. Yet, such a parallelization means that the model has no clue of the order of the words within a sentence. Every word is passed simultaneously without any sequential ordering. This is a major flaw as obviously the order information can drastically impact the meaning of a sentence. To counteract that, scientists manually injected the position information. The original method was as simple as passing the position number to the model. Over time, newer and more efficient methods have been introduced.
In the case of context window extension, this raises the question of how the model will react to longer sequences introducing positions it has never experienced during training. A large range of methods have been developed to address this and try to maintain the model’s performance on previously unseen sequence lengths.
The Algorithm
We identified the two main bottlenecks of long-context training (as being costly and time-consuming). The solution would be to address one or both of them during the training phase. The main idea would be to have two phases in the training. The first phase would be to train on a contained context window length, and the second phase would be to expand the context length by only using long context training data without focusing on adding knowledge. We could make this second phase extremely fast and cheap in comparison to the first training phase (or to a full long-context training).
Doing so would allow many more people to have access to long-context models, as they could leverage any model and make it long-context at a negligible cost (compared to the original pre-training). The one constraint we need to make sure is that the attention mechanism and the positional encoding used in the model we want to context-expand can be modified to a long-context-friendly model version without harming the original weights so that the model does not lose its capability or knowledge in the adaptation process.
Fortunately, plenty of methods have been focused specifically for the long-context application and worked perfectly in this case. We should also mention that most of the long-context positional encoding methods that can build on top of an existing one are usually designed for RoPE positional encoding.
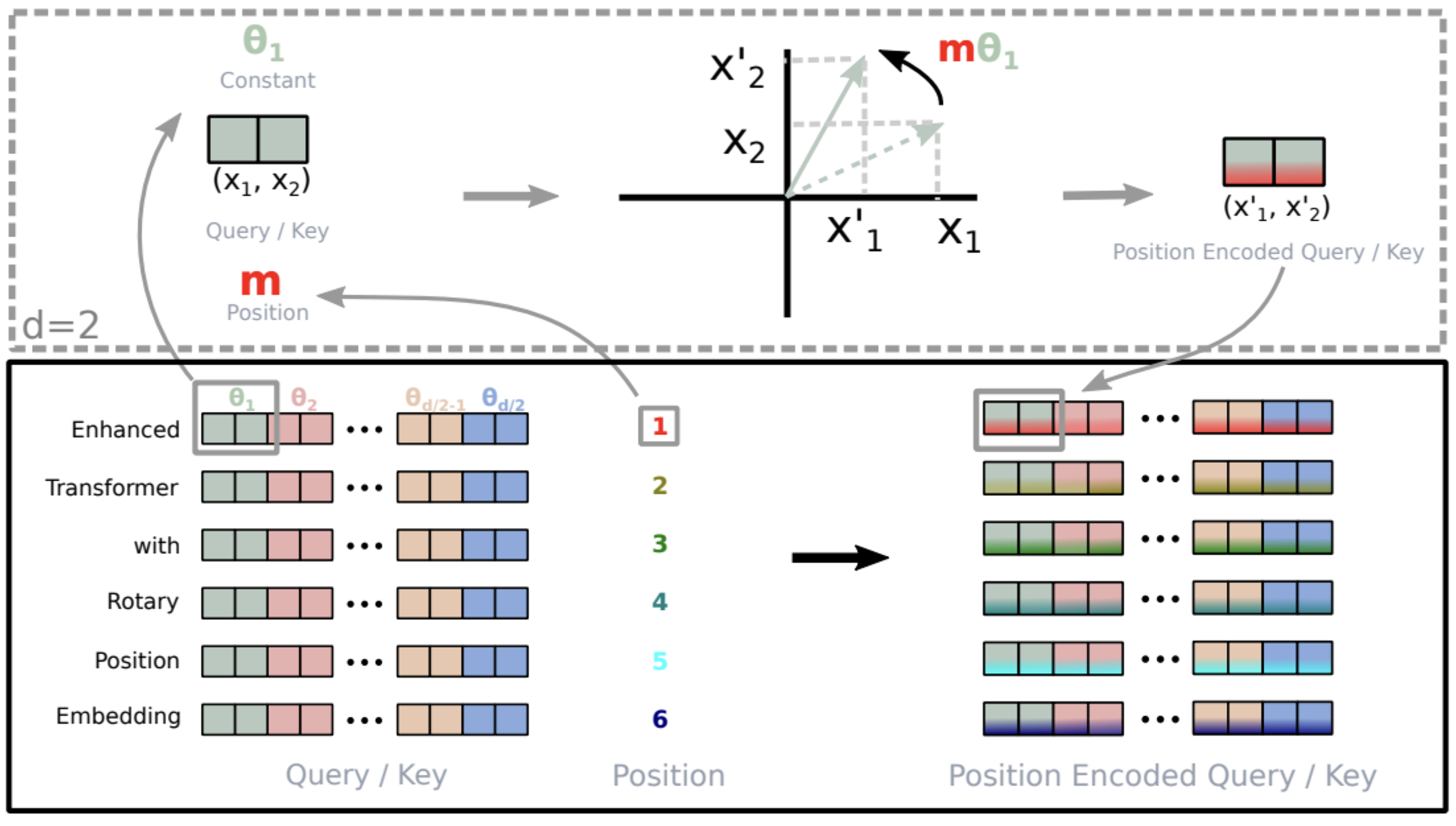
Figure 1: Implementation of Rotary Position Embedding (RoPE) from the RoPE paper
Well known current LLMs such as LLaMA, Mistral, and Falcon, are using the RoPE positional encoding, making our method easily adaptable to most open source LLMs.
Experiments
Objective
We chose to use Mistral-7B as our model to try the method as described previously. Mistral-7B was chosen as it is open-source, ubiquitous with top-tier performance for models of that size and multiple pretrained versions can be used as our baseline. Mistral-7B was trained on 8k-context inputs and by default used a 4k-Sliding Window Attention (SWA). The goal will be to fine-tune it into a 16k-context instruct version.
SWA is an approximated attention mechanism which makes the complexity linear with the sequence length. The model has a fixed attention window span around a word. As the Transformer blocks are stacked, the attention actually flows and expands from block to block making the actual attention span much larger to reach a span ~= nb_blocks x swa for the latest block. This is not unlike the idea of only using 3×3 kernel size in convolutional models and not requiring larger size kernels as long as the model has a large enough number of layers which allows to correlate a pixel to just its immediate neighbors to more and more distant pixels as the data flows through the layers, while the attention to closer pixels stays greater than the attention to the more distant pixels. The origin of this technique lies in the idea that close context is more important than long-range context and SWA naturally gives more weight to closer words.
We then naturally have access to a linearized attention, and we propose a long-context positional encoding. Fortunately, Mistral-7B was built with RoPE (Rotary Position Embedding) which possesses several extensions for long-context. We adopt the SOTA (at the time) positional encoding extension: YaRN (Yet another RoPE extensioN). YaRN re-scales the attention scores as a function of the sequence length and modifies the base of the rotation in RoPE following the frequency (to avoid loss of high frequency information during the PE scaling). The YaRN paper claims to perform best for context extension with and without fine-tuning.
LoRA
Because of limited resources, we consider training with the LoRA adapter. Our method is inspired from the LongLoRA paper which fine-tunes models for long-context using LoRA and shows great results. We target the attention matrices as our trainable parameters. Following the paper and to improve stability, we also release the normalization and embedding layers.
Strategy
Our fine-tuning has a double objective: extend the context window and turn the model into an instruct model. To do that we adopt a three-fold strategy. The first two steps are dedicated to increasing the context window of Mistral-7B, and the last one is used to teach the model to answer human-like questions. We describe them below.
- The first phase trains the model on nearly 13k samples (taken from the RedPajama2 dataset) of size exactly 16k while parameterizing YaRN to address 16k-context.
- The second phase continues this training but on 6k samples (also taken from RedPajama2) of various sizes ranging 0 to 16k and following a 1/x-like distribution. YaRN is parametrized to address 32k-context.
- The third phase fine-tunes the model on roughly 40k Q/A samples that result from a combination of the Long-Alpaca and UltraChat dataset (10k + 30k). The lengths of the examples also follow a 1/x-like distribution. We run two epochs. YaRN is parametrized to address 32k-context.
Additionally, we re-parametrized the SWA from 4k to 8k for all stages.
The second stage and the will to fine-tune on a length-distribution that favors the small sizes, comes from the idea that the natural distribution of text generation should follow this pattern. We usually want short and concise generation, as long-context generation is very sparse. This fixes the issue of long-context models generating endless or very long sequences when not required.
Results
Our final quantitative results are two sided. They indeed reveal a clear improvement on some tasks in specific frameworks when increasing the context length, but they also highlight the difficulty of the context extension techniques that currently exist.
| 500 | 2000 | 4000 | 8000 | 16000 | 24000 | 32000 | |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, no SWA) | 8.24 | 7.29 | 6.99 | 6.65 | 54.9 | 226 | 476 |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, with SWA) | 8.24 | 7.29 | 6.99 | 6.64 | 6.07 | 6.03 | 5.90 |
| Mistral-7B-v0.1-context_extension (our model) | 6.19 | 5.67 | 5.53 | 5.29 | 4.85 | 4.78 | 4.60 |
| 500 | 2000 | 4000 | 8000 | 16000 | 24000 | 32000 | |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, no SWA) | 8.24 | 7.29 | 6.99 | 6.65 | 54.9 | 226 | 476 |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, with SWA) | 8.24 | 7.29 | 6.99 | 6.64 | 6.07 | 6.03 | 5.90 |
| Mistral-7B-v0.1-context_extension (our model) | 6.19 | 5.67 | 5.53 | 5.29 | 4.85 | 4.78 | 4.60 |
Figure 2: Perplexity Score (the Lower the Better) for Different Context Sizes
The baseline model with 8K context length but without sliding window attention (SWA) clearly collapses once the context length is over 8k. Note that one particularity of generative models is that they tend to be overconfident as the context length increases. This is the reason why the perplexity score decreases as the context length increases.
| QuALITY | TOEFL | CodeU | TopicRet | |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, no SWA) | 44.06 | 61.34 | 2.22 | 22 |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, with SWA) | 42.57 | 62.08 | 0* | 62 |
| Mistral-7B-v0.1-context_extension (our model) | 47.52 | 60.97 | 1.11 | 33.33 |
| QuALITY | TOEFL | CodeU | TopicRet | |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, no SWA) | 44.06 | 61.34 | 2.22 | 22 |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, with SWA) | 42.57 | 62.08 | 0* | 62 |
| Mistral-7B-v0.1-context_extension (our model) | 47.52 | 60.97 | 1.11 | 33.33 |
Figure 3: Accuracy (the Higher the Better) of Different Closed-Form Tasks
QuALITY is a MCQ on document comprehension dataset, TOEFL gathers questions taken from the TOEFL exam, CodeU evaluates code comprehension, and TopicRet evaluates the capability of retrieving a passkey within a document.
*The value 0 just reflects the fact that the benchmark is very difficult. 1.11 and 2.22 are also bad values. For reference, GPT4o gets a score of 25.55 on this benchmark.
| Financial | Contract | Multidoc | |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, no SWA) | 39.62 | 16.1 | 18.17 |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, with SWA) | 40.57 | 21.27 | 19.37 |
| Mistral-7B-v0.1-context_extension (our model) | 26.34 | 12.7 | 17.87 |
| Financial | Contract | Multidoc | |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, no SWA) | 39.62 | 16.1 | 18.17 |
| Mistral-7B-Instruct-v0.1 (Context Length 8K, with SWA) | 40.57 | 21.27 | 19.37 |
| Mistral-7B-v0.1-context_extension (our model) | 26.34 | 12.7 | 17.87 |
Figure 4: F1 Score (the Higher the Better) for Different Open-Form Tasks (Text Generation for Different Domains)
Extending the context of an existing LLM (to 32K in our case) using fine-tuning techniques described above is most usually done at the cost of some capabilities of said LLM in other areas. While improving the perplexity score is relatively easy, it can be extremely difficult to consistently improve or maintain the performance of the LLM on defined tasks, especially open-form tasks like essay generation. That being said, for a vertical task that is clearly defined, one could leverage those techniques to perfect the performance of the LLM in this area. In other words, fine-tuning a foundation model into a long-context foundation model is hard with the tools currently available, but fine-tuning it into a task-specialized model is doable at a low computational cost.
Resources & Sources
- Code on GitHub : github.com/sade-adrien/llm_context_extension
- Attention Mechanism: linformer, longformer (swa), sparse transformer, longnet, reformer
- Position Encoding: review of PE in context extension, rope, ntk-aware scaling, position interpolation, yarn, alibi
- Fine-tuning: lora, longlora
- Other: flash-attention, mistral-7b