Introduction
Clinical note summarizers have great potential for enhancing medical documentation efficiency and have great market demand. These tools aim to alleviate the administrative burden on healthcare professionals, allowing them to focus more on patient care rather than tedious paperwork.
In an era where healthcare systems are increasingly adopting digital solutions, condensing complex and often lengthy clinical notes into concise, accurate summaries is not just an innovation but a necessity. However, creating such tools comes with significant challenges, such as hallucinations and poor-quality summaries. This blog will explore the techniques and challenges, as well as introduce our original and effective way in generating clinical note summarizations, shedding light on how our method can mitigate hallucinations in this area.
Problems and Challenges
Two of the major challenges that we face when summarizing clinical notes are factual inconsistencies with the original clinical notes and omission of critical information due to the inherent nature of summarization tasks.
Factual inconsistency refers to cases where asserted facts in the summaries are actually not backed by the original clinical note. This can happen in two ways, either by presenting a completely wrong fact inconsistent with the facts in the world, or by talking about things not mentioned in the original text.
Another critical problem identified with medical data summarization is the omission of important facts, or “content hallucination”. Summarization, by its own nature, involves condensing information, and in doing so, the large language models might leave out essential details. The problem arises when these omissions are not just minor details but critical information that could lead to significant misinterpretation. As the definition of hallucination differs among authors, this issue of “content hallucination” is sometimes overlooked in works on abstractive summarization. In the context of medical applications, these errors are particularly concerning and something we should absolutely want to avoid.
These challenges lie in the fact that large language models lack domain-specific considerations to decide which fact or key words should be included in the medical summary. For illustration, consider the following sample source text and summary:
Source Text
Brief Hospital Course
Brief Hospital Course: Mr. ___ is a ___ male with history of multiple myeloma on Daratumumab/Pomalidomide/Dex who presents from clinic with dyspnea, abdominal pain, and elevated bilirubin.
# Elevated Bilirubin: Unclear etiology. ___ medication related, possibly doxepin or pomalidomide. Abdominal pain has resolved. RUQ US negative for biliary process. LFTs improving at time of discharge. Possibly intermittent hemolysis as indirect was elevated. Please continue to monitor.
# ___: Patient found to have evidence of ___ esophagitis given oral thrush on exam and odynophagia. He was prescribed a 14-day course of fluconazole for total duration to be determined by outpatient providers. Also checked baseline QTc which was 400. Please continue to monitor.
# Dyspnea: Normal O2 sats at rest and ambulation. Does not appear in respiratory distress. CTA chest unremarkable. Resolved at time of discharge.
# Acute Kidney Injury: Cr 1.3 on admission, baseline 0.9-1.1. Likely due to poor PO intake. Improved with IVF.
# Hyponatremia: Mild. Likely hypovolemic due to poor PO intake. Improved with IVF.
# Multiple Myeloma: Relapsed, refractory IgG Lambda multiple myeloma currently on Daratumumab/Pomalidomide/Dex. Continued Bactrim and acyclovir for prophylaxis. Follow-up with outpatient Oncologist
# Depression/Anxiety: Multiple stressors in life. Follows with Psychiatrist Dr. ___. Severe anxiety and insomnia. Held home doxepin. Continued Lexapro and clonazepam.
# Anemia/Thrombocytopenia: Counts at baseline. All lines down on ___ likely ___ IVF and stable on recheck.
# Abdominal Pain: Unclear cause. Currently resolved.
# Gout: Continued home allopurinol.
# Chronic Pain: Continue gabapentin and Tylenol.
# Severe Protein-Calorie Malnutrition: Patient with weight loss and poor PO intake. He was seen by Nutrition.
==================== Transitional Issues: ==================== – Patient found to have evidence of ___ esophagitis given oral thrush on exam and odynophagia. He was prescribed a 14-day course of fluconazole for total duration to be determined by outpatient providers. – Patient had baseline EKG with QTc of 400 given interaction between fluconazole and escitalopram. Please continue to monitor QTc. – Patient with mildly elevated bilirubin on admission which normalized without intervention. Please consider intermittent hemolysis and continue to monitor LFTs. – Please note CTA chest with mild bibasilar fibrotic changes. – Please note abdominal ultrasound with splenomegaly of 15.5cm. – Patient’s doxepin held at time of discharge. Please ensure follow-up with Psychiatry. – Patient was seen by Nutrition given evidence of malnutrition. – Please ensure follow-up with Oncology.
# BILLING: 45 minutes spent completing discharge paperwork, counseling patient, and coordinating with outpatient providers.
*Please note that sensitive information are not collected to protect the patients’ privacy.
Reference Summary
Hospital Summary Written by Medical Professionals
You were admitted to the hospital for shortness of breath, abdominal pain, and elevated liver numbers. For your shortness of breath, you had a chest CT scan which did not show any blood clots in your lungs. It did not show any cause for your difficulty breathing. Most importantly, your breathing improved while in the hospital and you were having no symptoms when being discharged. Your abdominal pain also resolved. You had an ultrasound of your liver that did not show a biliary cause of your elevated liver numbers. This improved the following day and your Oncologist will continue to monitor. You also reported throat discomfort with swallowing. You had signs of a fungal infection in your mouth. This throat pain is likely due to a fungal infection in your esophagus. You were started on a medication called fluconazole. This should help your symptoms improve. Please discuss how long you should continue this medication with your outpatient providers. We did stop your doxepin which may have been causing some of your side effects.
The reference summary avoids mentioning myeloma, a very serious disease, focusing instead on the immediate issues for which the patient visited. However, large pre-trained models tend to be verbose and end up mentioning the history of myeloma. This demonstrates the challenge of deciding which pieces of information to include in the summary, even when some details that should be omitted are seemingly important.
Key Qualities for Effective Clinical Note Summarizations
With the two problems of summary generation in mind, we have identified these three qualities that would be very desirable to have in the generated summaries.
1. Selective Inclusion and Exclusion
Implement a mechanism to control which information from the original text is included or excluded, rather than relying solely on the language model.
2. Conciseness
Reduce the length of the clinical notes while retaining essential information. This ensures that the summary is both efficient to read and effective in conveying the necessary details.
3. Preservation of Original Terminology
Maintain the original terminology used by clinicians to ensure accuracy and consistency. Since these summaries are intended for healthcare professionals who may need to refer back to them, preserving the precise language from the clinical notes is essential. Simplifying or altering terms could cause confusion and reduce their reliability as a reference.
Proposed Solution: Keyword-Augmented Summarization
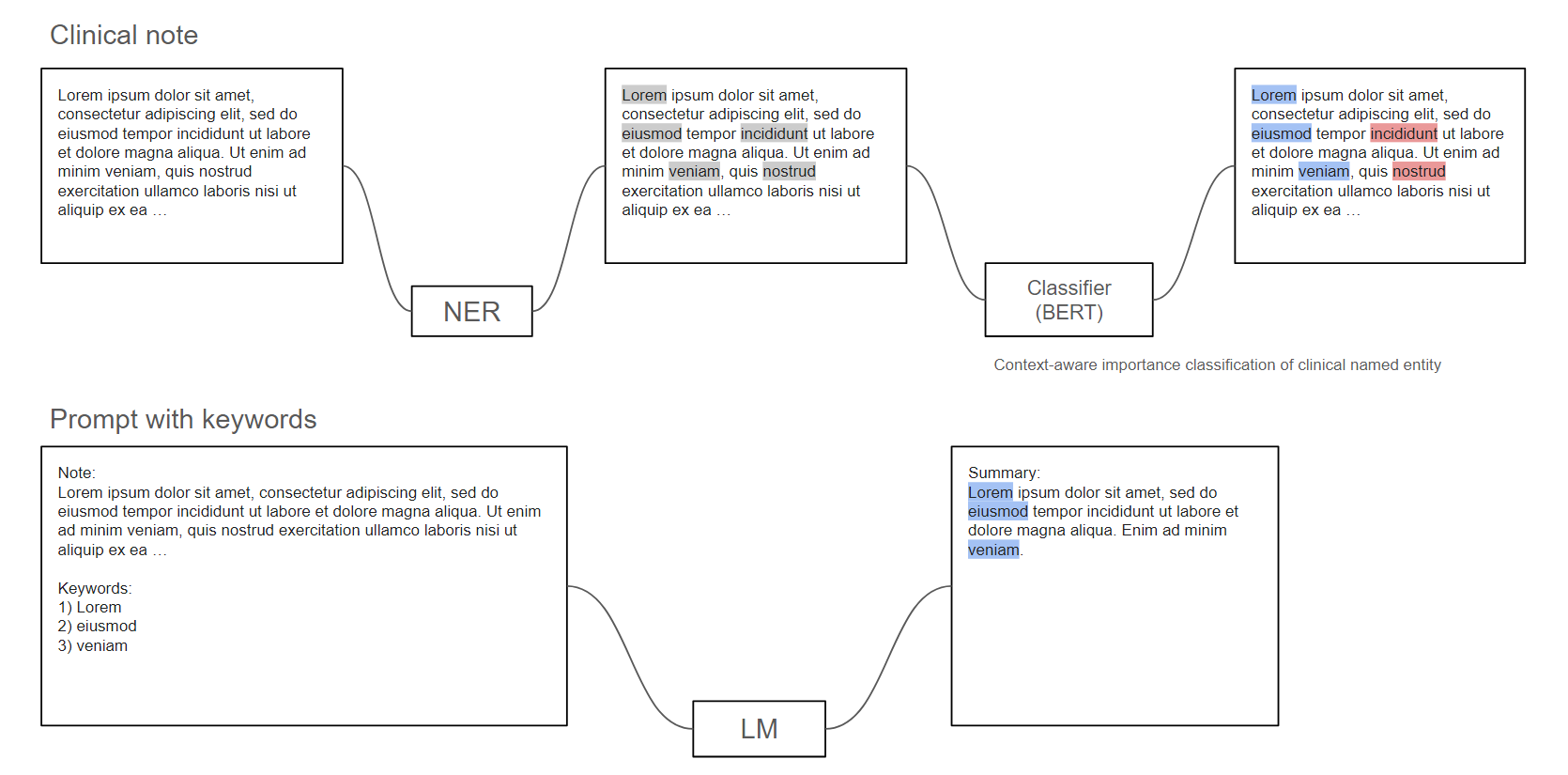
Figure 1: Workflow of Our Pipeline
To address the challenge of generating high-quality clinical note summaries, we propose a structured pipeline comprising three essential modules: a Named Entity Recognition (NER) model, a Keyword Importance Classification model, and a large language model for generating the summaries.
We leveraged BERT-based models for the NER and keyword classification tasks and used Llama3 as the language model for inference.
Workflow of the Proposed Pipeline
The process begins with the clinical note, which serves as the input. The first step is passing this text through the NER model, which identifies and extracts relevant medical keywords, such as diagnoses, symptoms and so on.
Next, these extracted keywords, along with the original input text, are fed into the Keyword Importance Classification model. This module determines whether each keyword should be included in the final summary or not. Our next section will focus on our methodology of designing and training this module.
Finally, the selected keywords are used to prompt the large language model, instructing it to generate a summary with particular emphasis on the selected keywords. The result is a clear and focused summary tailored to the medical context and aligned with the needs of healthcare professionals.
Advantages of the Pipeline
Let’s explore the advantages of our proposed keyword selection and prompting method, and why it is particularly well-suited for summarizing clinical notes:
- Reduces False Negatives: By prompting the LLM with critical keywords, we can significantly lower the chances of important details being missed and ensure important information is included in the summary.
- Combines with Other Hallucination Mitigation Techniques: This method works well alongside strategies that are designed to reduce false positives, enhancing the overall accuracy of the summaries. For the project, we have combined our method with a decoding strategy that is known to reduce factual inconsistencies, which are similar to false positives in the summary.
- Tailored to Domain-Specific Requirements: This method prioritizes terms and phrases that are particularly relevant to the medical domain. By focusing on clinical terminology, diagnoses, treatments, and procedures, it produces summaries that align with the specific needs of healthcare practitioners.
Keywords Selection: Designing and Training
The key feature in our pipeline is our exploration on how to provide a high-quality list of keywords as a prompt to the language model.
Motivation
1. Keywords provide critical clues for identifying the valuable content that should be included in the summary.
There are two ways of generating summarizations:
Extractive: identify important sentences from text and generate summarization verbatim.
Abstractive: write a summary involving paraphrasing or writing novel sentences.
The abstractive method usually generates more natural summarizations, and our keyword-guided prompt will ensure the precision. Our method is motivated by how humans write summaries, as humans try to contain the important keywords in the summary and perform necessary modifications to ensure the fluency or grammatical accuracy.
2. Get model to focus on the key content on top of the “summarize this” instruction.
Guide the model with specific keywords so that we ensure the language model pays attention to information that is most appropriate to be included in the summary and essential information is not omitted. This is particularly important in medical summaries, where missing key terms can lead to significant misinterpretations or loss of critical information.
3. Proven enhancement in summary generation.1,2,3
Previous studies have demonstrated that incorporating keywords enhances the quality of abstractive summarization, improving both relevance and focus in the generated content.
Core Problem
Here is an example of the entities recognized by the NER model, where the keywords are highlighted:

Figure 2: Highlighted Keywords Recognized by NER Model
We need to address the question of which keywords should go into the summary. To answer this, we decided to train a keyword classification model which performs binary classification for each named entities. The class (should be included or shouldn’t be included) depends on several factors:
- Global Context: It should take global context into consideration, so that we ensure the decision to include a keyword is based on the overall relevance of that keyword within the broader context of the note.
- The Class of Related Named Entities: It will also be affected by the classification of other keywords. For example, the inclusion of a specific diagnosis might depend on the context provided by related medication or symptoms.
- Entity Type: Different types of keywords, such as diagnosis, medications, or symptoms, may have varying levels of importance. For example, we’ve observed that dosages were extremely unlikely to be mentioned in the summaries. The model should be trained to account for these differences.
Base Model Choice: Longformer
We built our keywords selection module on Longformer. To accommodate for the often lengthy nature of clinical notes, we decide to leverage Longformer for longer contexts. Longformer is a variant of BERT, designed with a more efficient self-attention mechanism, which allows the model to process sequences up to 4,096 tokens, ensuring that most clinical notes can be fit entirely in one window. By maintaining access to the full text context, the model can better understand the relationships between keywords and their surrounding information, leading to more accurate classification and summarization.
Meanwhile, Longformer can capture interdependencies among text, entity types, and keyword classes, as mentioned in the core problem section. By recognizing these interdependencies, the model ensures that the selected keywords are both relevant and meaningful within the clinical context.
To optimize the task for BERT’s capabilities, we structure the keyword classification task to align with BERT’s strengths, transforming it into a masked token prediction problem. This setup not only simplifies the classification process but also leverages BERT’s pretraining, which is designed to predict masked words within a sequence.
Together, these advantages ensure that our keyword selection model is effective and practical, and that it will provide a list of high-quality keywords for the next step.
Methodology
The most important, non-trivial component of this model is the entity classifier. We outline the model description and training pipeline below.
Entity Extraction
Using a dataset of doctor-written patient summaries, which includes pairs of clinical notes and the corresponding doctor-written patient summaries, and a pre-trained clinical NER model, we first extract the named entities with its classes in both the clinical note and the summary. By identifying which keywords appear in the summary, we can put a binary label on each named entity in the source text. Here, we introduce two new special tokens.
<ent>, </ent>
The first two mark the boundaries of a named entity within a text, so that we can clearly define where each keyword begins and ends, making it easier for the model to focus on these entities during classification.
Labeling
Meanwhile, we introduce two more new tokens to indicate if the entity should be included in the summary.
<0>, <1>
Specifically, <0> indicates that the keyword should not be included, and <1> indicates it should be included. However, the key problem in our data preparation is how to generate high-quality <0> or <1> labels, since simply labeling by exact character matching will return terrible results.
To generate high-quality labels, we’ve considered the following scenarios where we should label the entity as <1>:
- Exact Character Matching: “dizziness” – “dizziness”
- Acronyms: “CAD” – “Coronary Artery Disease”; “MRI” – “Magnetic Resonance Imaging”
- Abbreviations: “trops” – “troponins”; “Dx“ – “Diagnosis“
- Generalization: “pMIBI stress” – “a stress test”; “HCTZ” – “diuretic medication”
- Language difference: “Heart” – “καρδιά”
These keywords that are mentioned indirectly should also count as <1>. We used the GPT-4o assistant API processing 1k clinical note/summary pairs to help identify if the keywords do appear in summary, either directly or indirectly.
Dataset Augmentation and Training Target
We augmented the clinical notes to make the format more suitable for the Longformer classification task and ensured that named entities were clearly labeled and aligned with the model’s input requirements. Here is an example:

Figure 3: Example of Augmented Clinical Note
The training process would involve masking only the special <0>or<1>tokens and learning to predict those masked binary tokens.
Prompting and Inference
Once we have identified the important keywords through our classification process, the next step is to guide the language model in generating the summary. We compared the summary quality based on two dimensions: prompting strategies and decoding strategies.
Prompting Strategies
We explored prompting as the format of (source, [keyword1, keyword2, ...]) in two ways: inclusive and selective.
Inclusive Prompting:

Figure 4: Inclusive Prompting Example
-
We feed the keywords that the model confidently predicts to be
<1>into the prompt, instructing the model to include these keywords. -
“You are an assistant summarizing given clinical notes. Ensure to mention the given keywords naturally within the summary.”
Selective Prompting:

Figure 5: Selective Prompting Example
-
It may be necessary to exclude certain keywords, and we instruct the model to both include the important keywords and avoid mentioning unnecessary keywords.
-
“You are an assistant summarizing given clinical notes. Ensure to mention the given keywords naturally within the summary. Do not include any of the nontarget keywords in the summary.”
Decoding Strategies
Aside from the two prompting strategies, we enhance the factual accuracy of the generated summaries by employing advanced decoding strategies. Since the language model generates text one word at a time—predicting the next word based on the previously generated context—the choice of decoding method can greatly impact the quality of the summary. Simple methods like greedy results in subpar summaries, and even beam search, which evaluates multiple possible sequences simultaneously, may fail to deliver optimal results.
DoLa4, which stands for decoding by contrasting layers, is a recent work to mitigate factual inconsistencies in language model generation. This method enhances factuality in both multiple-choice and open-ended generation tasks by contrasting the output probabilities from different transformer layers. Specifically, it treats the output probabilities of the final layers as “expert” predictions while considering those from the middle layers as “amateur” predictions. This approach capitalizes on findings that factual knowledge in large language models is typically concentrated in specific transformer layers, leading to more accurate and reliable text generation.
Results
The first metric for Named Entity labeling are listed as below:
| Metric | Result |
| Precision | 0.66 |
| Recall | 0.95 |
| F1 | 0.78 |
Figure 6: Normal Classification Task Metric Results
We have only included the normal classification task metrics, instead of character-based matching methods and semantic similarity methods, since we have taken many exceptional scenarios into considerations. With a limited size dataset, we have reached the F1 score of 0.78, which already can help provide a high-quality list of keywords into the language model prompts. We have planned new experiments with larger and more diverse datasets in the future.
Also, we have confirmed the effectiveness by human evaluation of the summarization quality by comparing 3-shot In-Context Learning (ICL) prompting with keywords augmentation with naive 3-shot ICL prompting, which contains a naive system prompting: “summarize this”. We also take other metrics into consideration like compression ratio, which is the number of tokens in summary divided by the number of tokens in the source clinical note, and inference time.
| Prompting Strategies | Decoding Strategies | Compression Rate | Inference Time |
| Inclusive | Greedy | 0.577±0.243 | 8.135±2.326 |
| Beam Search | 0.623±0.253 | 11.225±3.272 | |
| DoLa | 0.590±0.259 | 10.021±2.362 | |
| Selective | Greedy | 0.389±0.168 | 5.715±2.126 |
| Beam Search | 0.430±0.171 | 8.445±3.676 | |
| DoLa | 0.404±0.175 | 7.278±2.398 |
Figure 7: Compression Rate and Inference Time Metrics for Different Prompting and Decoding Strategies
During testing for these metrics, inclusive prompting generally achieves a higher compression rate than selective prompting across all decoding methods, which results in longer inference times and more computation. Greedy decoding consistently yields the lowest inference time. If minimizing inference time is the priority, selective prompting with greedy decoding is the fastest (5.715 ± 2.126).
Demo Video
Here is the demo video for our clinical notes summarizer, with different choices of decoding strategies and prompting strategies. We show an example with the selective prompting strategy.
Figure 8: Clinical Notes Summarizer Demo
Reference
- Li, H., Zhu, J., Zhang, J., Zong, C., & He, X. (2020). Keywords-Guided Abstractive Sentence Summarization. Proc. AAAI, 34(05), 8196–8203.
- Nguyen, H., & Ding, J. (2023, June 19). Keyword-based augmentation method to enhance abstractive summarization for legal documents. Proc. ICAIL 2023.
- Liu, Y., Jia, Q., & Zhu, K. (2021, April 19). Keyword-aware abstractive summarization by extracting set-level intermediate summaries. Proc. WWW 2021.
- Huang, Y.-S., Xie, Y., Luo, H., Kim, Y., Glass, J., & He, P. (2023). DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models (Version 2). arXiv. DoLa: Decoding by Contrasting Layers Improves Factuality in Large…
- Beltagy, Iz. Peters, Matthew E., Cohan, Arman. (2020) Longformer: The Long-Document Transformer. arXiv., Longformer: The Long-Document Transformer