Whisper is a family of speech-to-text models released by OpenAI. The official implementation uses PyTorch, an ML framework that is very convenient for its ease of use. This post discusses how the Whisper models were converted from PyTorch to ONNX, which is the main input format for Esperanto Technologies’ ML compiler.
The resulting ONNX models in FP16 precision can be found in our Huggingface page.
Whisper's architecture
Whisper follows the typical Transformer structure composed of an encoder model and a decoder model. The encoder takes the spectrogram of a piece of audio as input and produces an embedding sequence that represents the speech in a certain embedding space. The decoder completes the transcription into text, represented as a sequence of tokens, in an autoregressive manner. That is, given a partial sequence and the audio embeddings, the decoder predicts a probability distribution for the next token of the sequence.
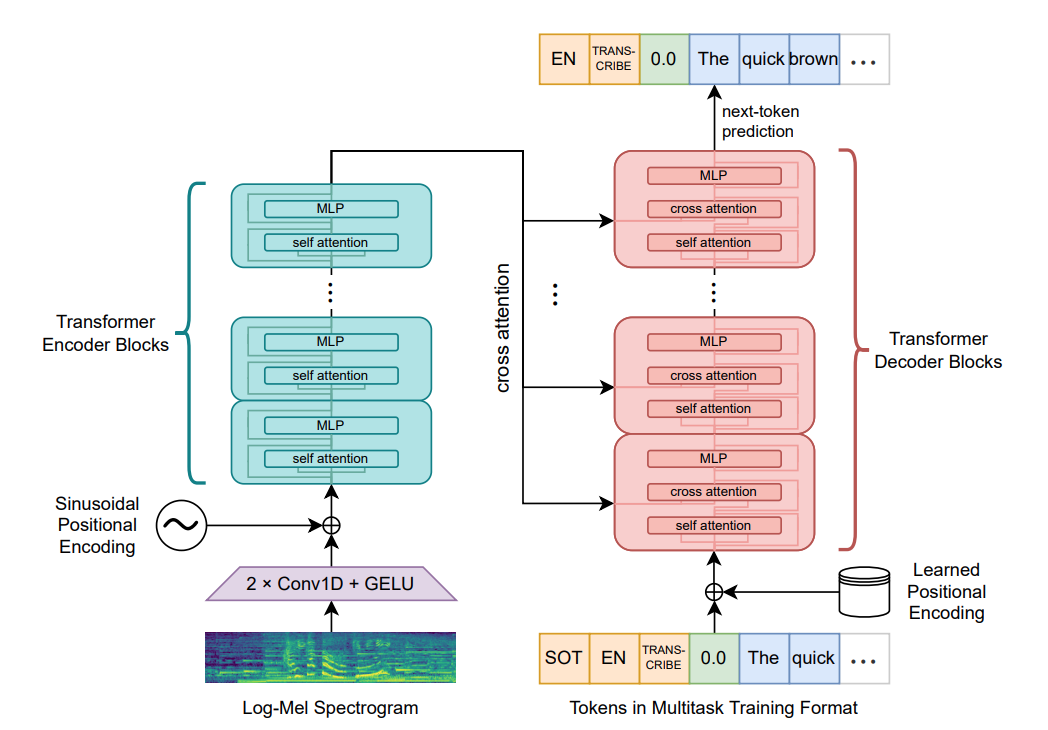
Whisper architecture. Diagram taken from the original paper by OpenAI.
Since there are two parts with clearly distinct use patterns, our goal is to obtain two corresponding ONNX models. For every transcription task, the encoder is executed exactly once but the decoder is executed as many times as necessary until the text is complete. Moreover, a few of the computations originally placed in the decoder depend only on the output of the encoder. Therefore, these nodes can be moved to the end of the encoder to avoid repeated computations.
| Whisper version | Number of parameters |
| Tiny | 39 M |
| Base | 74 M |
| Small | 244 M |
| Medium | 769 M |
| Large | 1550 M |
All versions of Whisper are quite small in comparison to most text-to-text language models. Thus, memory is no limitation to run Whisper in a single ET-SoC-1 device, even at FP16 or FP32 precisions. KV-caching, a common optimization technique that reduces computation by slightly increasing memory usage (enabled by leveraging the autoregressive nature of the decoder), can also be implemented on the device. More details about our KV-cache implementation can be found in the previous blog post. Similarly, the output tensors of the encoder part —which are common inputs for all the decoder part inferences— can stay on the ET-SoC-1 device throughout the process.
PyTorch to ONNX conversion
PyTorch provides a function torch.onnx.export() to export in ONNX format. However, that works by running the model once with user-provided inputs to obtain execution traces that can then be converted to an ONNX graph. This means that behaviour that depends dynamically on the input is not captured.
The official implementation of Whisper’s decoder part has conditional branches to create (for the first inference) or enlarge (for subsequent inferences) the KV-caches, which cannot be captured in an ONNX. Fortunately, PyTorch models are simply Python classes inheriting from torch.nn.Module and they are usually defined by composition from smaller models. Thus, it is quite easy to create new models using the pretrained components of the official Whisper model in the desired way and then export those new models.
To do so, we adapted Tadao Yamaoka’s script to better adapt the models to the particularities of ET-SoC-1. We factored computations outside of loops to avoid repetitions, we modified the inputs and outputs of the models, and we implemented KV-caches following a sliding window approach. For PyTorch models that are open-source, such modifications tend to be simpler at PyTorch level than at ONNX level.
Audio lengths impact inference speed
Esperanto Technologies’ ML compiler can produce better performing compiled models whenever tensor dimensions are static and multiples of certain internal hardware features, such as the size of cache lines or the length of vector registers. This is due to the way data is aligned across the memory hierarchy and the parallel memory access patterns. All these features are usually nice powers of two, so having tensors with dimensions that are divisible by relatively high powers of two helps performance. The compiler is usually able to pad tensors to obtain the desired alignment, but that is not always possible and sometimes involves adding extra copy operations that can compromise the benefits.
Whisper is trained to work with 30 seconds of audio. Shorter audios are padded and longer audios have to be cut. In the preprocessing steps, the 30 seconds are sampled in overlapping windows of 25 milliseconds each starting every 10 milliseconds. This translates to the model having tensors with dimensions of sizes 3000 and 1500. These numbers are divisible only by small powers of 2.
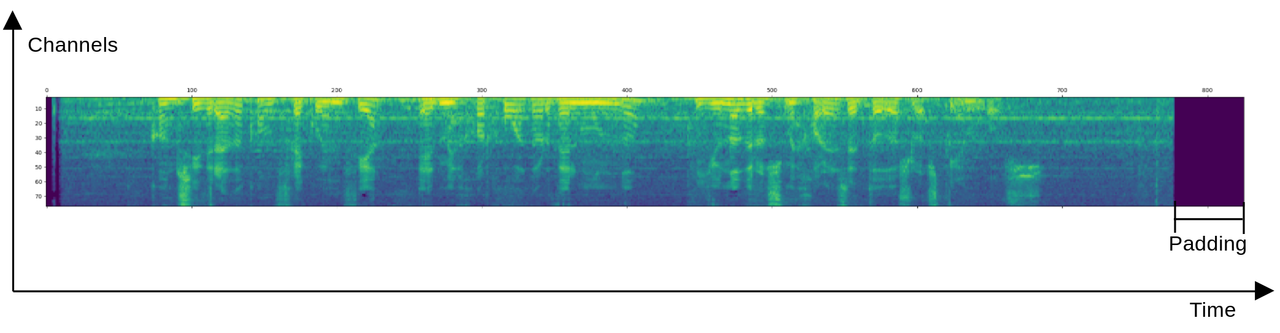
Visualization of a spectrogram with padding at the end of the audio.
A natural question arised: does the model operate correctly if we work with shorter audio lengths instead? In particular, 28.8 seconds of audio yield tensor dimensions of sizes 2880 and 1440, which are divisible by 32, while not being far from the original 30 seconds.
We decided to verify it experimentally. To do so, we considered more than 4400 audio samples from the AMI Meeting Corpus dataset —among those in the test split, the samples between 2.5 and 16 seconds— and compared the transcriptions obtained with the original Whisper (padded to 30 seconds) and a modified model using 16-second audio samples. The transcriptions were compared in terms of word error rates and character error rates as well as by visual inspection and there were barely any differences. This result seems aligned with the fact that the model is able to produce quite accurate transcriptions of short audios with a lot of padding.
The ONNX models were finally created with a symbol timesteps which is equal to the audio length in centiseconds. This parameter can in principle be any number up to 3000 (although functionality has only been checked with a few values). The best inference speed is achieved when this number is a multiple of 64. Apart from that, the smaller this number, the better the speed because the audio to process is shorter.
Sources
AMI Meeting Corpus. https://huggingface.co/datasets/edinburghcstr/ami
OpenAI. “Introducing Whisper”. https://openai.com/index/whisper/
OpenAI. “Robust Speech Recognition via Large-Scale Weak Supervision”. https://cdn.openai.com/papers/whisper.pdf
OpenAI. Whisper’s official implementation. https://github.com/openai/whisper
PyTorch. “TorchScript-based ONNX exporter”. https://pytorch.org/docs/stable/onnx_torchscript.html
Tadao Yamaoka. Whisper to ONNX conversion script. https://github.com/TadaoYamaoka/whisper/blob/main/to_onnx.py