Objectives
This blog post aims to explore the impact of incorporating generative models into a robotic decision-making framework. We explain how fine-tuned foundation models address limitations of traditional robotic frameworks in terms of planning, reasoning and adapting to dynamic environments. We present experimental results from a proof-of-concept robotic framework utilizing fine-tuned open-source Small Language Models (SLMs) for robotic systems. This blog provides a detailed analysis of two distinct pipelines employed in our experiments, along with a comprehensive discussion of the challenges and limitations encountered when applying language models to general-purpose robotic systems. Furthermore, we explore research opportunities that could enhance the efficiency of Esperanto platforms in executing general-purpose robotic frameworks. This exploration encompasses an examination of potential areas for further investigation, with the overarching goal of advancing the field of robotics and expanding the capabilities of autonomous systems. Through this work, we seek to contribute valuable insights to the ongoing development of more versatile and adaptable robotic systems, paving the way for future innovations in the field of robotics.
Overview
The remarkable success of Large Language Models (LLMs) in recent years has reignited interest in the pursuit of Artificial General Intelligence (AGI) for robotic applications. This renewed focus stems from the unprecedented capabilities demonstrated by models like GPT-3, GPT-4, and their counterparts, which have shown an ability to understand and generate human-like text, reason across diverse domains, and even exhibit problem-solving skills previously thought to be uniquely human.
The potential application of language models to robotics is particularly exciting, as it promises to bridge the gap between language understanding and physical interaction with the world. Researchers envision robots that not only process natural language commands but also understand context, intent, and nuance, leading to more intuitive human-robot interactions. This convergence of language models and robotics could potentially unlock new frontiers in areas such as:
- Adaptive manufacturing, where robots can respond to complex, context-dependent instructions
- Healthcare assistance, with robots capable of nuanced communication with patients and medical staff
- Domestic service robots that can perform household tasks described in natural language
- Educational robots that can adapt their teaching methods to individual learners
However, significant challenges remain in translating the success of language models to embodied AI systems (robots that can perceive, act and collaborate). These include grounding language in physical reality, developing more robust sensorimotor skills, and ensuring safe and ethical operation in unstructured environments. Despite these hurdles, progress in language models has injected new optimism and resources into AGI research for robotics, with many experts believing that we are closer than ever to creating truly intelligent and versatile robotic systems.
As this field advances, it continues to attract substantial investments from both private and public sectors, fueling rapid developments and raising important questions about the future of work, human-AI collaboration, and the broader societal impacts of increasingly capable robotic systems.
Benefits of Small Language Models to Robotics Frameworks
Traditional robotic frameworks typically rely on well-defined, modular pipelines to enable autonomous navigation or interaction with the environment. These systems use sensor fusion techniques, path planning algorithms, and control mechanisms to process sensory data, make decisions, and execute actions. For instance, in industrial settings, a robotic arm might be programmed to recognize and manipulate objects on a conveyor belt using Finite State Machines and optimizations, while a mobile robot might navigate a warehouse by following a predefined path and avoiding obstacles using different simultaneous localization and mapping (SLAM) techniques.
However, classical control methods have several drawbacks, notably limited adaptability. For example, a robotic arm in a traditional setup requires pre-defined instructions for each object it encounters. If an object is misaligned or if a new object type is introduced, the robot may fail to complete the task, as it cannot adapt without reprogramming. Similarly, a mobile robot that relies on a predefined map and sensor data may struggle to navigate effectively if the environment changes unexpectedly or if it encounters obstacles not accounted for in its original programming. These systems are heavily dependent on structured data and precise models, making them less effective in dynamic or inaccurate modeled environments.
Recent advancements in Small Language Models (SLMs) have begun to transform this traditional pipeline, introducing new possibilities for more flexible and adaptive robotic systems. SLMs can be integrated into robotic frameworks to enhance natural language understanding, enable more sophisticated task planning, and improve decision-making capabilities. For example, instead of manually programming a robot for specific tasks, SLMs allow robots to interpret high-level natural language commands such as “pick up the red cube and place it on the top shelf” and autonomously generate the corresponding action sequence.
Research by Kagaya et al. (2024) demonstrated how language models could generate complex robotic manipulation plans directly from natural language instructions, effectively bridging the gap between human intent and robot execution. Similarly, Wang et al. (2024) explored the use of language models for few-shot learning in robotics, enabling robots to quickly adapt to new tasks with minimal training data. These developments highlight the potential of LLMs to create more generalizable and intuitive robotic systems capable of understanding and responding to complex commands.
In contrast to classical methods, SLMs offer significant advancements in flexibility and adaptability. For instance, with SLMs, a robot could handle variations in object type, size, and position without the need for explicit reprogramming, allowing it to complete tasks more effectively even in unpredictable situations. In the case of autonomous navigation, an SLM can interpret high-level commands like “navigate to the loading dock while avoiding any obstacles,” dynamically adjusting to changes in the environment without relying on a fixed map or extensive pre-modeling.
In summary, while traditional robotic frameworks have been effective in specific, controlled environments, the integration of SLMs offers significant advancements in flexibility, adaptability, and human-robot interaction. SLMs provide a powerful tool for enabling robots to perform complex, context-aware tasks, making them more capable in diverse and dynamic environments. By overcoming the rigidity and limitations of classical control methods, SLM-enhanced robotics represents a significant step forward in the development of more intuitive and responsive robotic systems.
Esperanto Platform Overview
Esperanto Technologies’ ET-SoC-1 is a high-performance, energy-efficient AI inference processor designed to address the growing demands of machine learning applications. This system on chip (SoC) leverages RISC-V architecture and features over 1,000 energy-efficient ET-Minion cores alongside high-performance ET-Maxion cores. Future members of the ET-SoC family will build upon the strengths of the ET-SoC-1, focusing on further improvements in energy efficiency, compute density, memory size, and versatility. These advancements could potentially address several key requirements of robotic frameworks:
- Low power: The ET-SoC family’s emphasis on energy efficiency aligns well with the need for low-power operation in mobile, non-tethered robotic applications. The ability to perform complex computations with minimal energy consumption could significantly extend the operational time of battery-powered robots.
- Small form factor: The integration of many cores and accelerators into a single SoC allows for a compact design, which is crucial for robotics applications where space and weight constraints are often significant factors. A small form factor enables the development of more agile and versatile robotic platforms.
- High performance: The ET-SoC family will provide the necessary horsepower for running complex AI models and robotic control algorithms while maintaining efficiency. This efficient resource usage is particularly important for enabling real-time processing of multi-modal inputs and adapting to dynamic environments, which are critical for general-purpose robotic tasks.
These features position the ET-SoC family as a promising platform for addressing the computational needs of advanced robotic frameworks, potentially enabling more capable and efficient robotic systems in the future.
Evaluating a Robotic Framework Using Open-Source Language Models
As part of the goal of this thesis is to evaluate the capability of off the shelf open-source Small Language Models, and its ability to reason, plan and generate robot control sequences running on the ET-SoC accelerator platform, we chose 2 separate pipelines to evaluate the effectiveness of such pipelines.
Pipeline #1: Baseline Modularized Robotics Foundation Model Pipeline
The first pipeline consists of three core modules: Small Language Models (SLMs) -(i.e. Phi-3-mini) , a Vision Assistant (i.e Grounding Dino), and a specialized robot motion module.
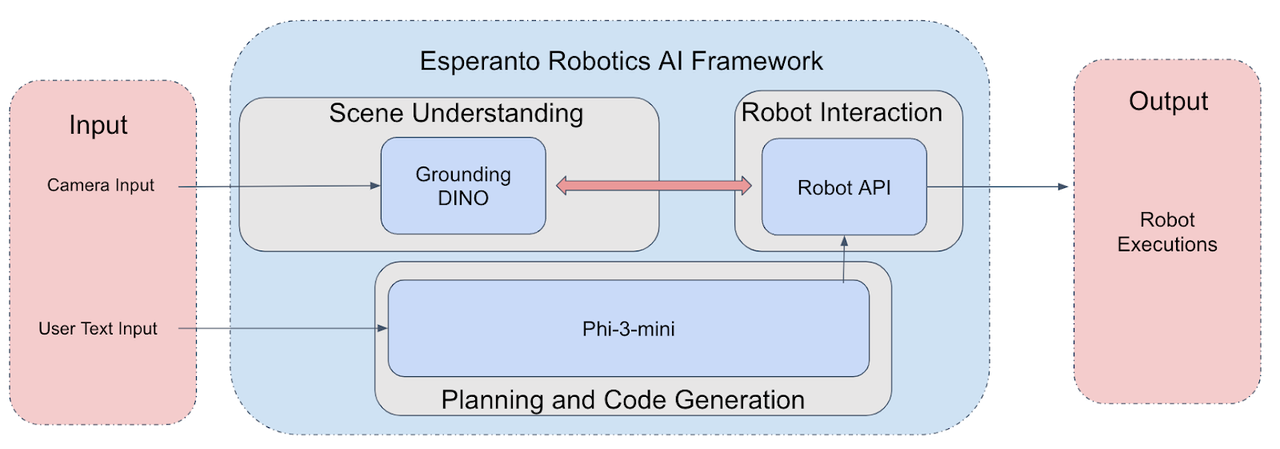
Figure 1: Modularized Robotics Foundation Model Pipeline
Each component plays a critical role in enabling seamless interaction between user input and robotic execution.
- Small Language Model (SLM): The primary function of the language model in this pipeline is to interpret and process user commands provided as text (i.e. stack the red cube on top of the green cube). The SLM is tasked with understanding the context and intent behind the input command, and subsequently generating a comprehensive plan for the robot to materialize the user intended behavior per the input command. This involves selecting and organizing pre-scripted motion primitives and generating executable Python code. This code will make calls to our custom robot motion APIs to manipulate the robot effectively. For this purpose, we utilize Phi-3-mini, a state-of-the-art SLM with 3.8 billion parameters. Out of the box, the model is not able to generate good plans or code. To enhance its planning and code generation capabilities, we have fine-tuned Phi-3-mini using Low-Rank Adaptation (LoRA) techniques on a curated expert dataset, ensuring it is well-suited to the specific demands of robotic task planning and execution.
- Vision Assistant: The Vision Assistant module is integral to the system’s ability to interact with the physical environment. It processes the camera input to understand and localize objects within the scene, making this information available for task execution. Specifically, we employ Grounding-DINO within this module, a powerful model capable of object detection and localization based on descriptive input. The Vision Assistant enables the generated code to retrieve precise object coordinates and dimensions, which are essential for accurate robot manipulation.
- Robot Visual and Motion APIs: The framework includes two main types of APIs: the Robot API and the Visual API. The Visual API interacts with the Vision Assistant to gather detailed object information from the environment. Once this information is acquired, it is passed to the Robot API, which includes a set of predefined functions such as “open_gripper,” “close_gripper,” and “move_to_position.” These functions are designed to execute specific robotic actions based on the object data provided. This modular approach allows the system to perform complex tasks by combining visual perception with precise robotic control.
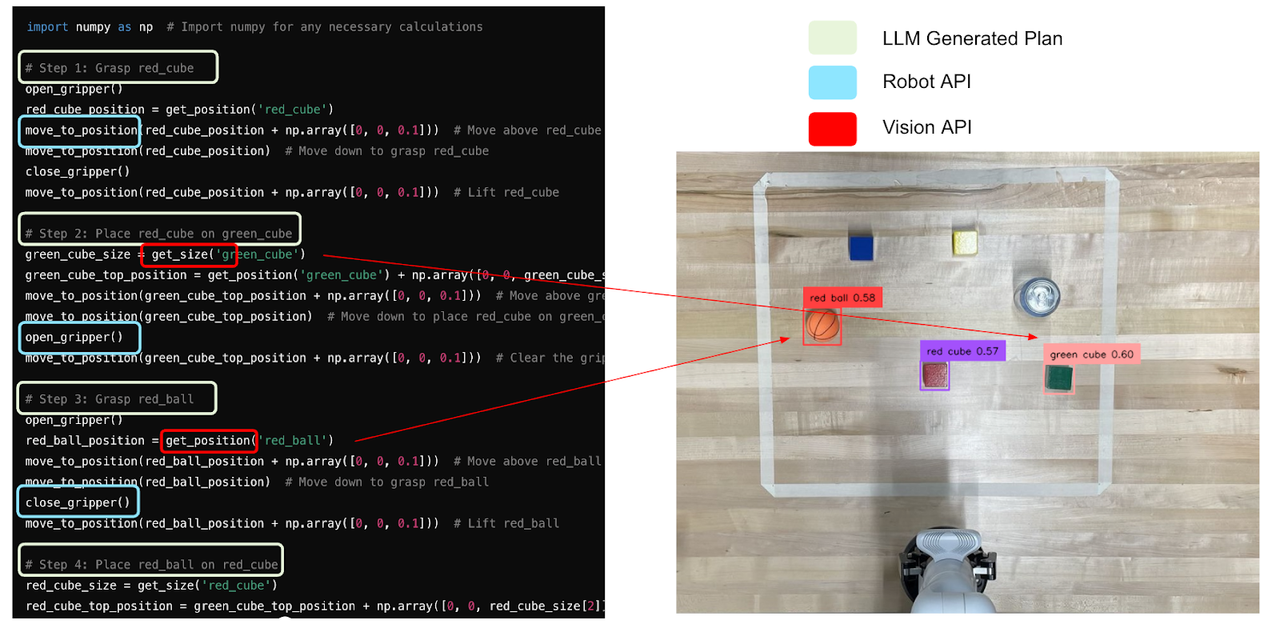
Figure 2: Example of Pipeline
As seen on figure above, the SLM generates the corresponding plan and necessary code, ensuring that the robot carries out the specified actions in real-time. The synergy between the SLM, Vision Assistant, and APIs enables the system to translate high-level user commands into concrete robotic actions, bridging the gap between human intent and machine execution.
Pipeline #2: End-to-End Robotics Foundation Models
One of the main challenges with the previous method was the prolonged time-to-execution, with a simple task taking approximately multiple seconds to begin execution, since the pipeline would first generate a plan, followed by the corresponding code (average ~ 350-400 tokens) prior to executing the code. To address this inefficiency, we proposed an alternative approach—Vision-Language-Action (VLA) Models—that allows for more immediate robot control via Large Language Models. The model we deployed is introduced in the OpenVLA paper, with model structure illustrated in Figure 2.
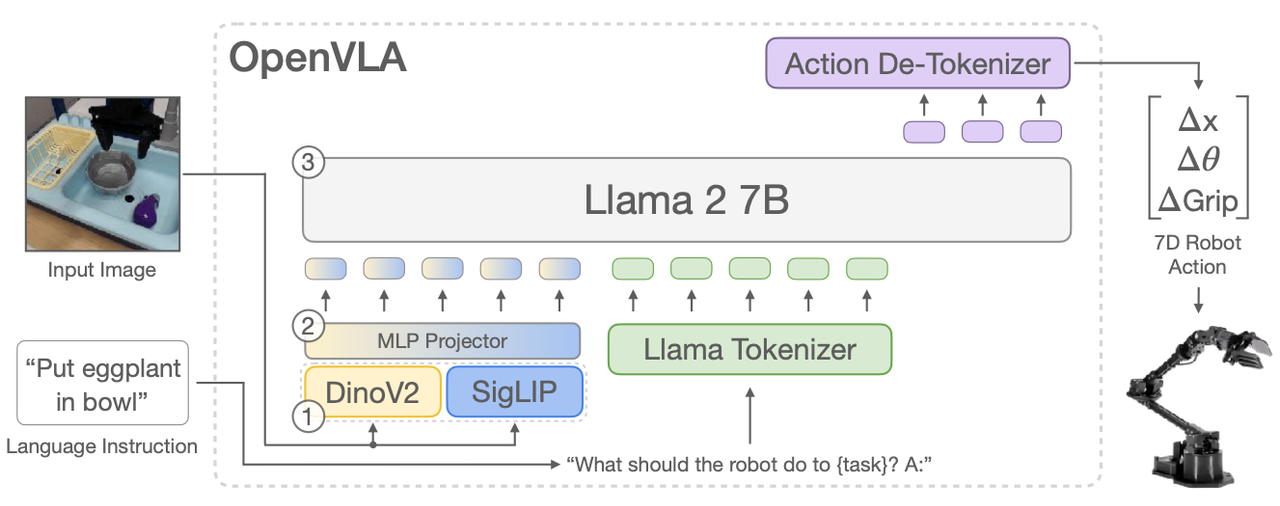
Figure 3: Open-Source Vision-Language-Action Model Architecture
OpenVLA is built upon the foundation of the pretrained Prismatic-7B Vision-Language Model (VLM) and integrates three key components:
- Fused Visual Encoder: This encoder combines the strengths of SigLIP and DinoV2 backbones to process image inputs, converting them into “image patch embeddings” that encapsulate the visual information needed for task execution.
- MLP Projector: The projector transforms these image patch embeddings into a format that is compatible with the input space of a large language model, facilitating seamless integration between visual perception and language processing.
- Llama-2-7b language model: Serving as the core of the OpenVLA model, Llama-2-7b processes the projected embeddings to generate tokenized output actions. These tokens are then decoded into continuous, actionable commands via the Action De-Tokenizer, enabling the robot to execute the desired tasks directly.
This architecture significantly reduces the time between command input and action execution, making OpenVLA a more efficient and responsive solution for real-time robotic control.
Evaluation Environment
To assess the performance of both these pipelines, we utilized the Robosuite simulation framework, which is powered by the MuJoCo physics engine and widely used in robotics research. Robosuite provides a suite of benchmark environments, ensuring reproducibility and consistency in our evaluation. We customized the table-top manipulation environments within Robosuite to suit our specific evaluation needs. In both the real-world and simulation settings, we employed the Kinova-Gen3 robot equipped with a Robotiq 2F-85 gripper to carry out the tasks.
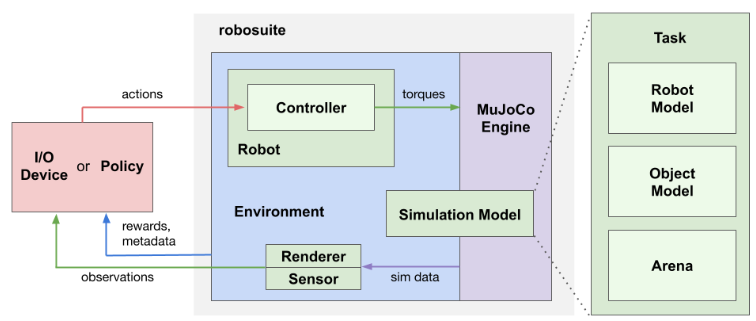
Figure 4: Block diagram of RoboSuite simulation framework
Baseline Modularized Robotics Foundation Model Pipeline
In our modularized pipeline, the primary task involves picking up specified objects and executing “stacking” tasks. We generated a fine-tuning dataset consisting of 800 task-specific text pairs using GPT-4. The input to the task is a user-provided description, such as “stack the red cube on top of the green cube” or “stack the red ball on top of the blue cube.” The language model is then expected to output a detailed plan accompanied by executable Python code. Each entry in the dataset includes a task description, a system prompt outlining the required scripted motion primitives, and a sequence of plans followed by the corresponding Python code.
Example generated code:

For this pipeline, we employed the open-source SLM model Phi-3-mini-4K-instruct, a state-of-the-art lightweight model with 3.8 billion parameters, trained on the Phi-3 datasets. This dataset encompasses a mix of synthetic data and carefully filtered publicly available data, emphasizing high quality and strong reasoning capabilities. For visual processing, we used Grounding-DINO in a zero-shot manner for object detection and localization, without additional fine-tuning.
Given the complexities associated with the automated evaluation of robot-generated code, we conducted human evaluations across 25 distinct scenarios. Each scenario represents a unique set of objects accompanied by a specific language instruction. For instance, one scenario includes three objects: a blue cube, a white ball, and a red rectangle. The corresponding language instruction is: “stack the blue cube on the table of the red rectangle, and then place the white ball on top of the blue cube.” The success rate is determined by human evaluators, who assess whether the task was completed successfully. Notably, the fine-tuned Phi-3-mini model achieved an impressive 96% accuracy in stacking tasks involving various objects compared with ground-truth GPT results which was generated by a trillion-size model. The single failure case occurred due to an incorrect identification of a pyramid’s properties, where the model attempted to place a ball on top of a pyramid instead of recognizing the invalidity of the command.
Due to the pipeline’s configuration, which generates detailed plans and code, the output sequences tend to be relatively long. For instance, in a task involving stacking two cubes, the sequence required approximately 350 tokens and took around 9.5 seconds to generate on an Nvidia A6000 GPU.
Challenges and Potential Solutions
The primary challenge posed by the current pipeline is the lengthy generation time, which hampers its applicability in dynamic environments where the scene or task may evolve during execution. One potential improvement lies in the development of high-level adaptive skills, such as “grasp_{object}“, in contrast to the current low-level motion primitives like “move_to_position“. This shift could lead to the creation of more adaptive and intelligent low-level motion primitives, significantly reducing the spatial and computational demands on language models, resulting in fewer tokens and faster execution times.
Additionally, the development of abstract plans could further enhance inference efficiency. Special tokenizers capable of generating abstract plans, rather than relying on explicit English text, could mitigate some of the execution issues. Alternatively, a robust scene-graph generation pipeline could be developed, allowing a language model to interpret scene information. With a constructed scene graph, real-time planning could be achieved through simple group searches, enhancing both speed and accuracy.
End-to-End Robotics Foundation Model Pipeline
To evaluate the OpenVLA framework in our novel settings, we adhered strictly to the fine-tuning and deployment protocols recommended by the authors. We collected 100 episodes of real-world data (the generated Reinforcement Learning Datasets formatted file can be found on GitHub) using the Kinova-Gen3 robot on the task “Lift Carrot” and fine-tuned the OpenVLA checkpoints over 5000 epochs. Please be sure to collect your own dataset before deployment, since every robot setup has a unique workspace and points-of-view. It is worth noting that collecting diverse actions with diverse objects will help improve the model performance. For more suggestions on fine tuning OpenVLA, please check the official Github Repository. After fine tuning, we tested the visual background generalization ability on a new robot. Due to the model’s nature of generating short output sequences, it was possible to achieve closed-loop control with an inference time of approximately 0.33 seconds per sequence generation.
The following video shows the output of the robot executing the user command “Put carrot on plate”.
Note in this scene, we show the capability of the robot’s visual aptitude to distinguish between different backgrounds.
Challenges and Potential Solutions
The current challenges with open-source VLA models are primarily related to shortcomings in its ability to perform long-horizon reasoning, planning, and execution accuracy. As noted by the original authors, the dataset used for pre-training (Open-X embodiment) consists mainly of motion-related task descriptions with relatively short sequences. Incorporating a Vision-Language Model (VLM) with chain-of-thought capabilities might enhance the model’s planning abilities. Alternatively, integrating this chain-of-thought reasoning directly into the OpenVLA Model during fine-tuning with long-horizon task descriptions and robot data could also improve performance.
Regarding execution accuracy, the model’s pre-training process, which relies solely on 2D image inputs, may not provide sufficient information for spatial motion planning. Incorporating additional modalities, such as depth data, tactile feedback, audio, or point cloud information, could lead to more stable and accurate execution outcomes.
| Current Vision-Language-Action Model (A100) | LLM-based TAMP + scripted motion API | |
| Fast Execution | 0.19s per action generation | 9.4s per plan and code generation |
| Relatively Small Model | 7B parameter for OpenVLA | Able to finetune Phi-3-mini on simple tasks |
| General-purpose cross-embodiment | Poor generalization across robot morphology | TAMP framework is the same, just need to change API based on robot |
| Data Generation | Real-world data, realistic simulation data | Spatial understanding ability, GPT-4o is the bottleneck? |
| Reasoning and Planning ability | Poor | Reasonable planning and reasoning |
| Ability to handle dynamic scene, different object grasping point | Able to incorporate within the fine tuning | Challenging task for scripted API |
Table comparing the performance of the two pipelines
Future Work: The Road Towards Embodied AI Agents
We draw inspiration from the human brain, where we envision a path where we are able to develop robot systems which are able to sense, reason and act autonomously in an energy efficient manner. Such a capability has been termed Embodied AI Agents by the robotic community.
The following pipeline represents such a system where the embodied agent is able to sense its environment, reason and perform specific physical actions, whilst using memory to learn and store new experiences.
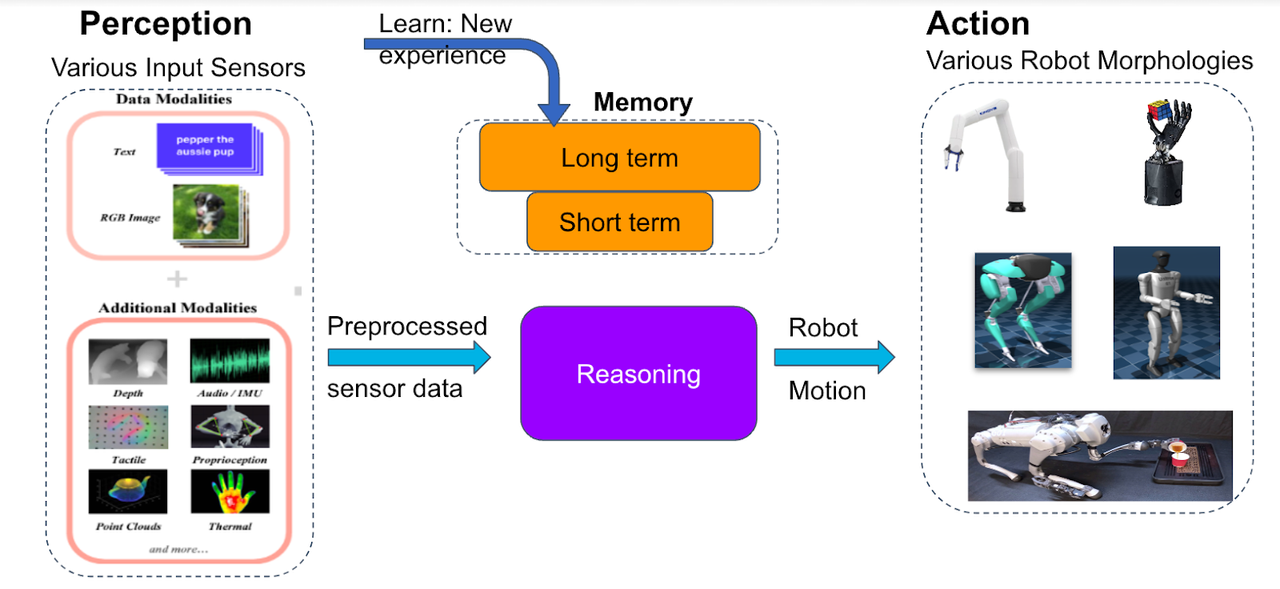
Embodied AI Agent Components
The perception phase is responsible for taking in multiple input sensors and data modalities. The primary data consists of text and RGB images, while additional modalities include depth sensing, audio/IMU, tactile feedback, proprioception, point clouds, and thermal imaging. These diverse inputs provide the agent with a comprehensive understanding of its environment.
The memory phase consists of two types of memory: long-term memory, which stores learned experiences and knowledge over time, and short-term memory, which handles immediate, temporary information processing. This phase continuously learns from new experiences.
The reasoning phase takes preprocessed sensor data as input and serves as the cognitive center where the agent operates. Here, the agent processes information, makes decisions, plans actions, and integrates information from both memory and current sensor data.
The action phase is responsible for outputting robot motion commands and can control various robot morphologies. These include robotic arms, humanoid robots, bipedal robots, and ground robots. This phase enables diverse physical interactions with the environment.
Example implementation of such a system can be visualized as follows:
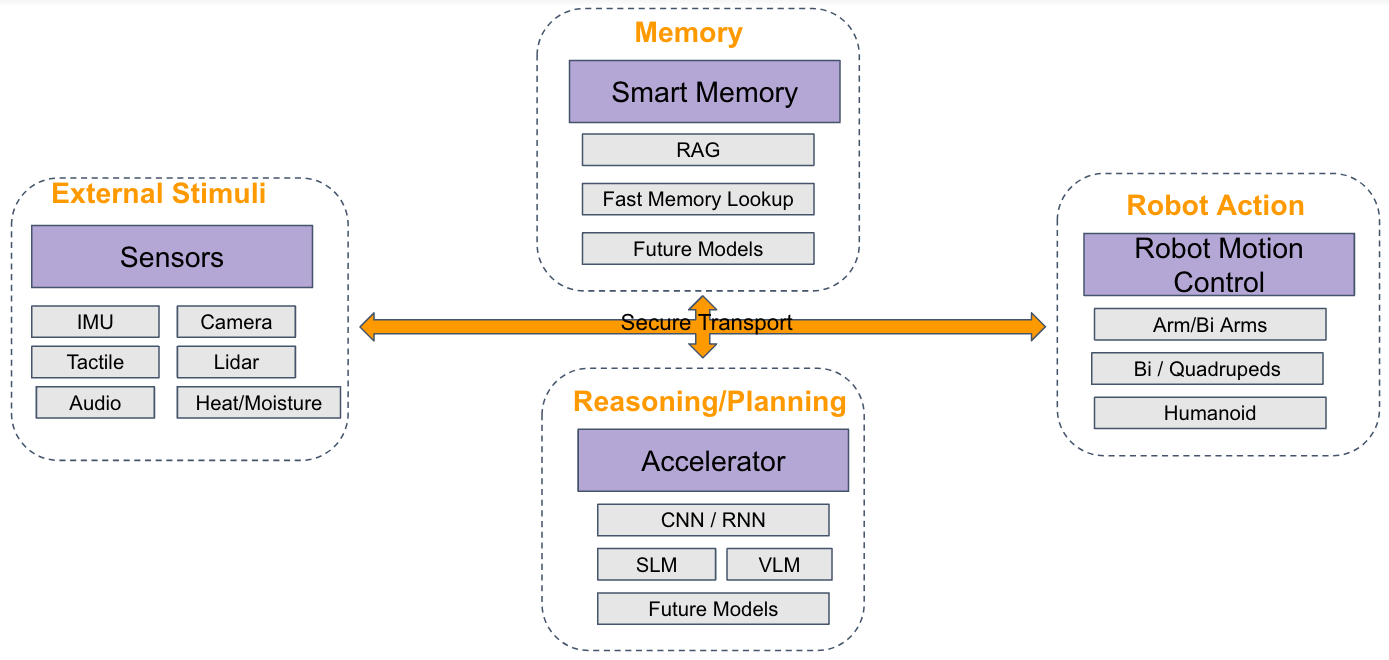
Example of energy efficient self-contained system
Here one can see different vendors and partners contributing to different components in this system. This would create a diverse ecosystem to enable more companies and research teams to contribute and develop a standard framework without locking in to any specific vendor.
Partner Collaboration Opportunities
We believe that realizing the embodied AI agent vision requires a strong community to work together to complement each other. We see opportunities to collaborate with partners who can bring in different expertise and contribute to an open source robotic framework.
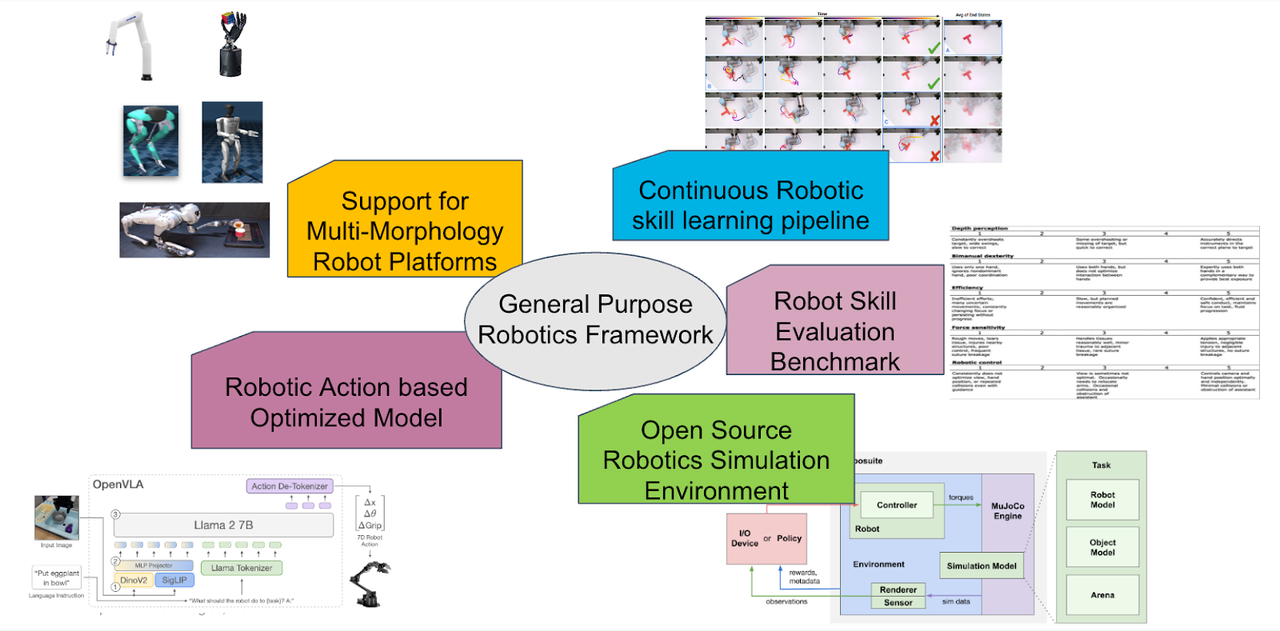
General purpose robotics framework
The framework centers around a “General Purpose Robotics Framework” that connects different components to create an ecosystem for developing and testing embodied AI agents. This integrated approach allows for:
- Cross-platform development
- Standardized evaluation
- Simulation-based training
- Real-world deployment
- Continuous skill improvement
An example of such a framework is AI Habitat which is a research platform for developing embodied AI models.
In summary, we are looking for partnership with any research teams and companies interested in building such a framework together for the benefit of the wider community.